はじめに
今回は第3回に引き続き具体的な手順のご紹介となります。今回は手順3~4の仮想マシンのハードウェア構成変更をご紹介します。
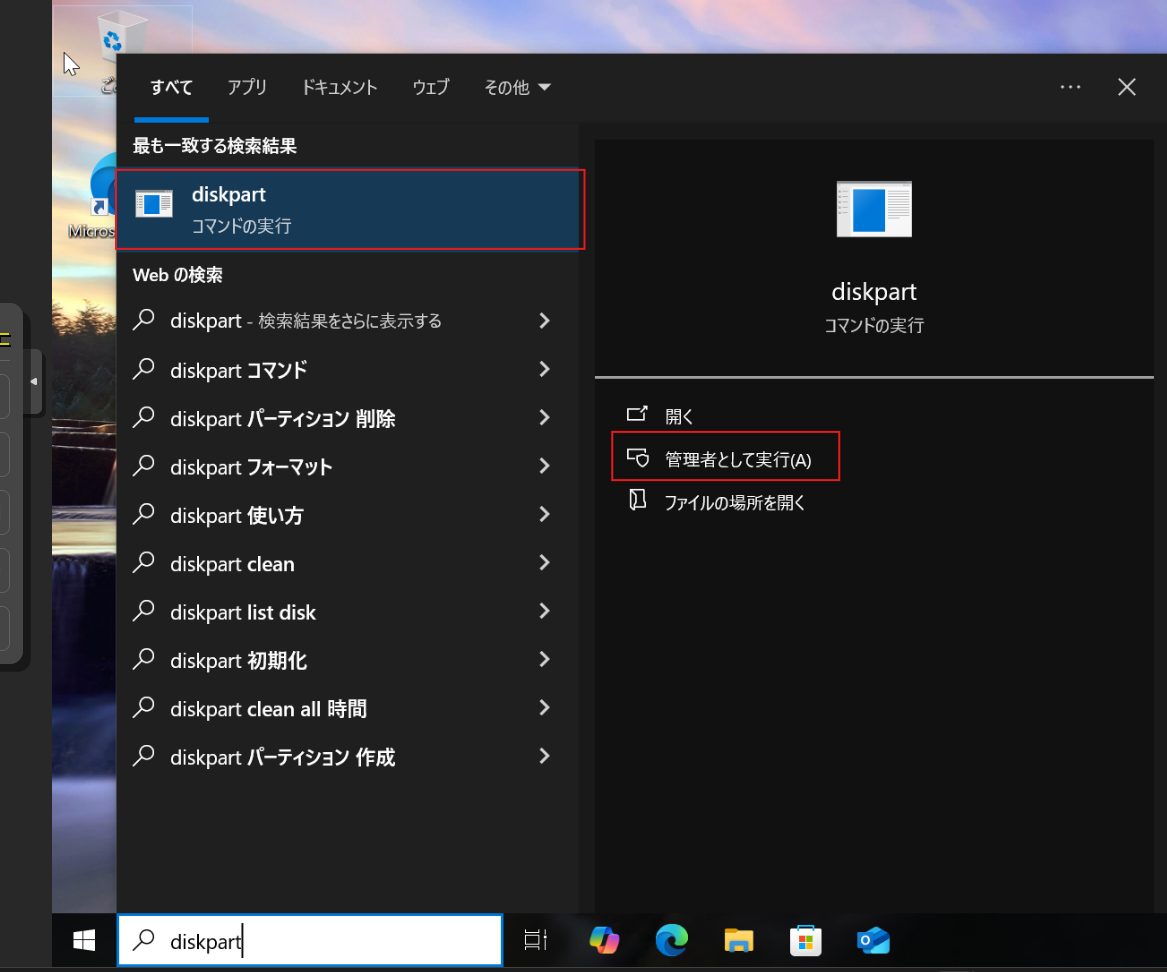
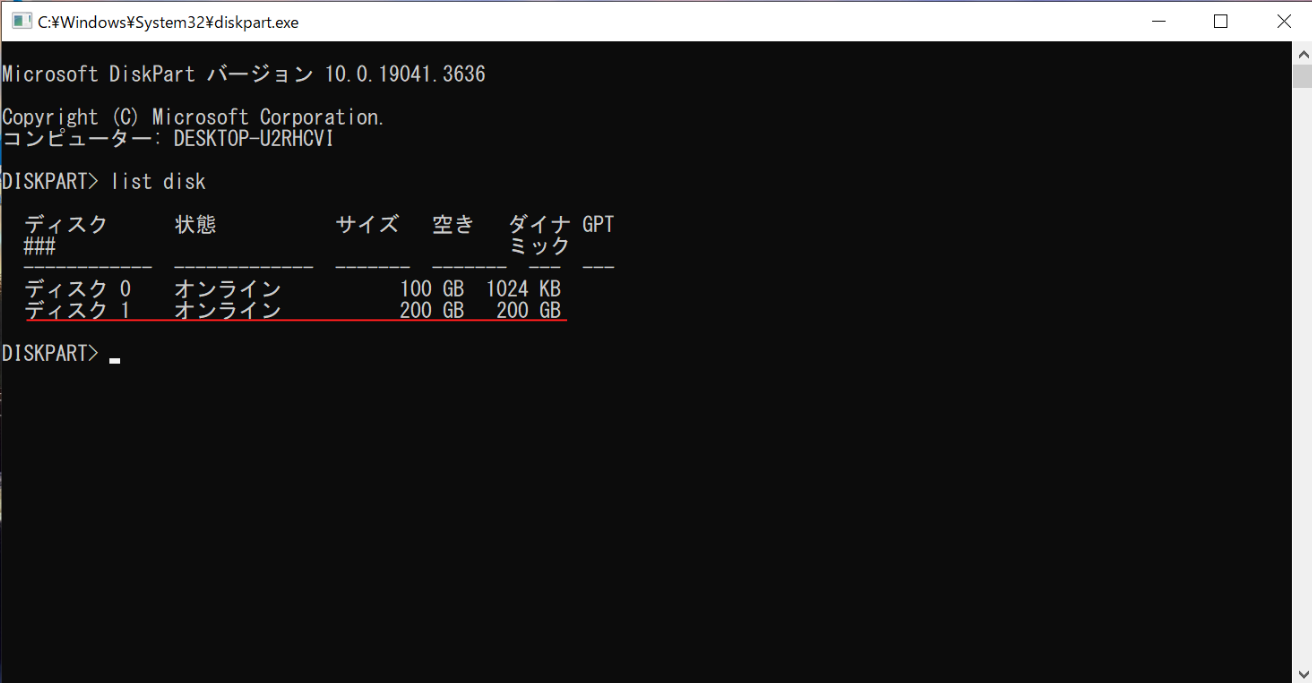
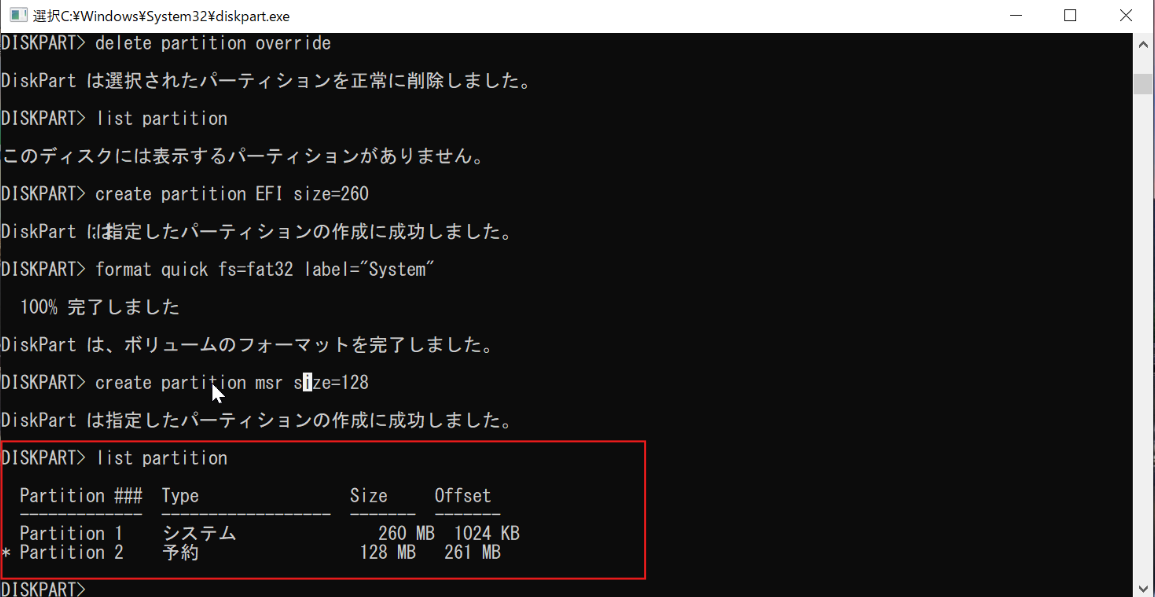
| 手順1:仮想マシンに Windowsの移行先の新規ターゲットディスク追加、パーティション作成 |
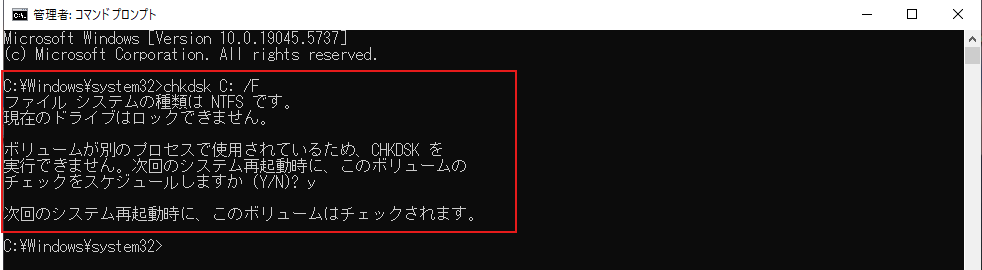
| 手順2: ソースディスク(既存のディスク)のプライマリパーティションのNTFS整合性チェック |
| ★手順3: 仮想マシンにTPMデバイスの追加 |
| ★手順4: 仮想マシンにEFIディスクの追加 |
| 手順5: gpartedによる既存ディスクのプライマリパーティションをターゲットディスクにクローン |
| 手順6: ターゲットディスクのプライマリパーティションのブート構成をEFIシステムパーティションに作成 |
| 手順7: ターゲットディスクからWindows10をUEFIブートで起動しディスクの管理からプライマリ領域の拡張を実行 |
| 手順8: Windows 11 インストール アシスタントを使用してアップグレード |
手順3: 仮想マシンにTPMデバイスの追加
設定前
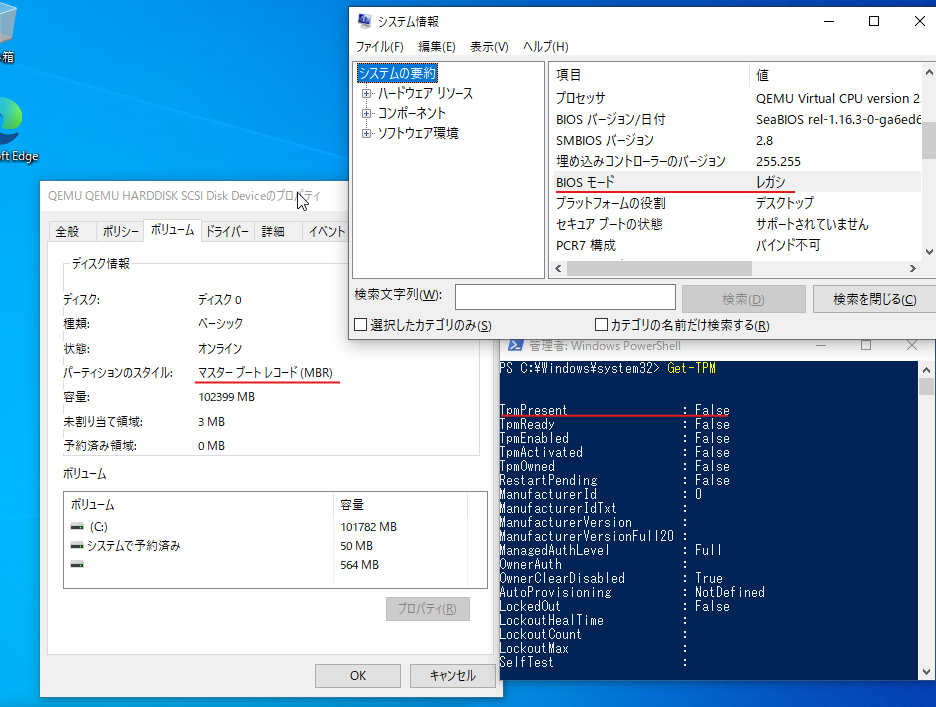
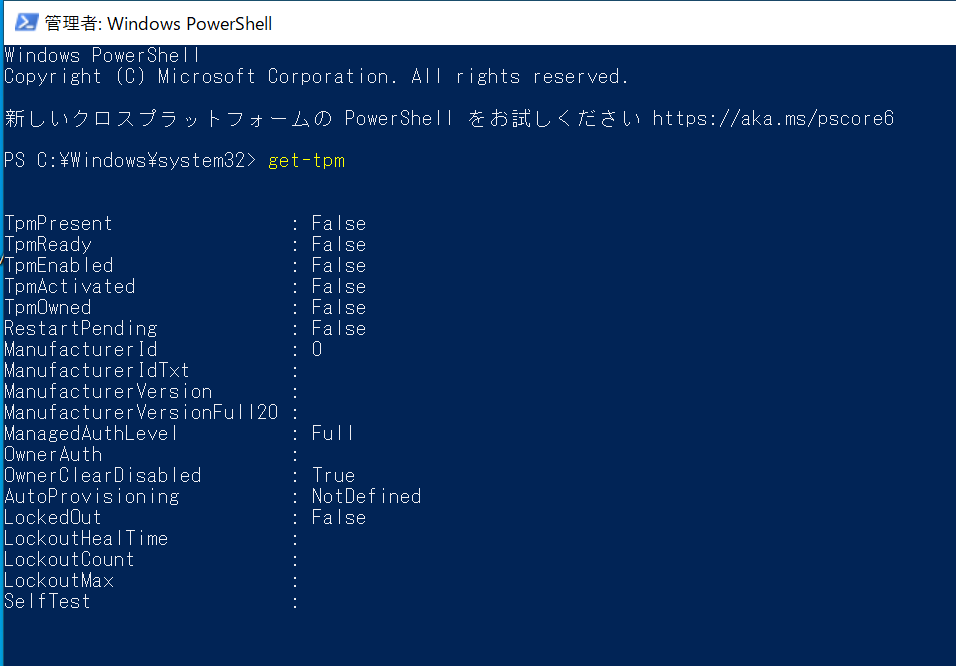
仮想マシンWindows10上のTPMの認識状況です。Powershell上でGet-TPMと実行すると確認できます。
TPM PresentがFalseとなっています。
設定
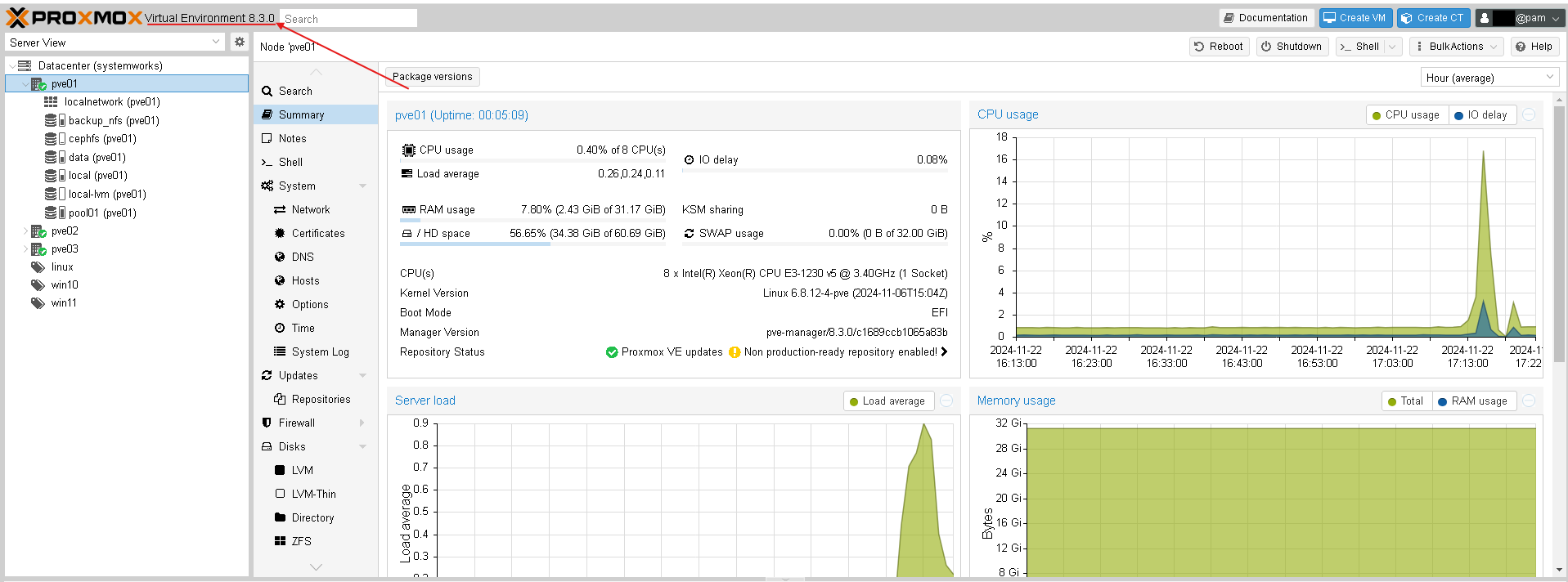
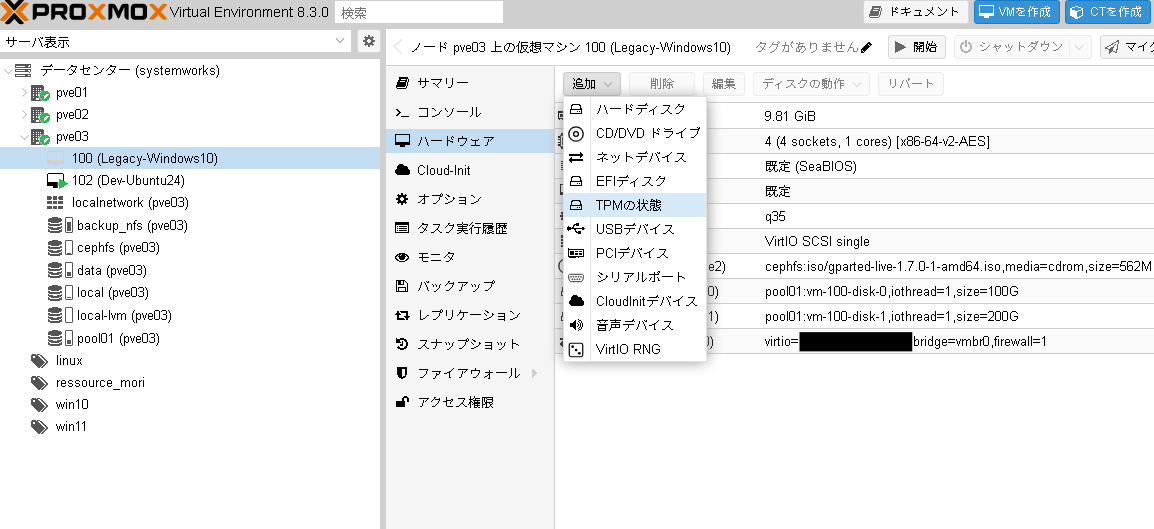
ProxmoxVEのWeb管理画面から対象のVMのハードウェア設定に進み、追加から「TPMの状態」を選択します。
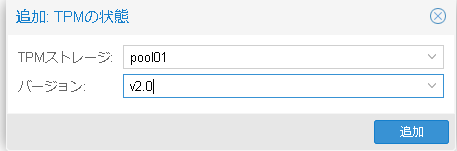
追加:TPMの状態というウインドウが表示されるのでTPMストレージとバージョンを選択して追加ボタンを押します。
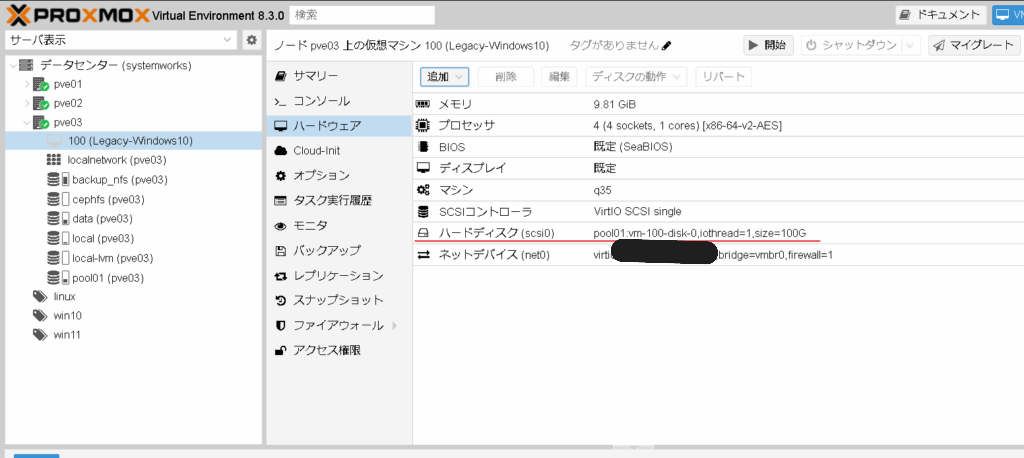
ストレージは仮想マシンのディスクイメージを配置しているストレージと同じ場所が良いと思います。(当社の検証環境ではpool01がディスクイメージのストレージでした)
設定後
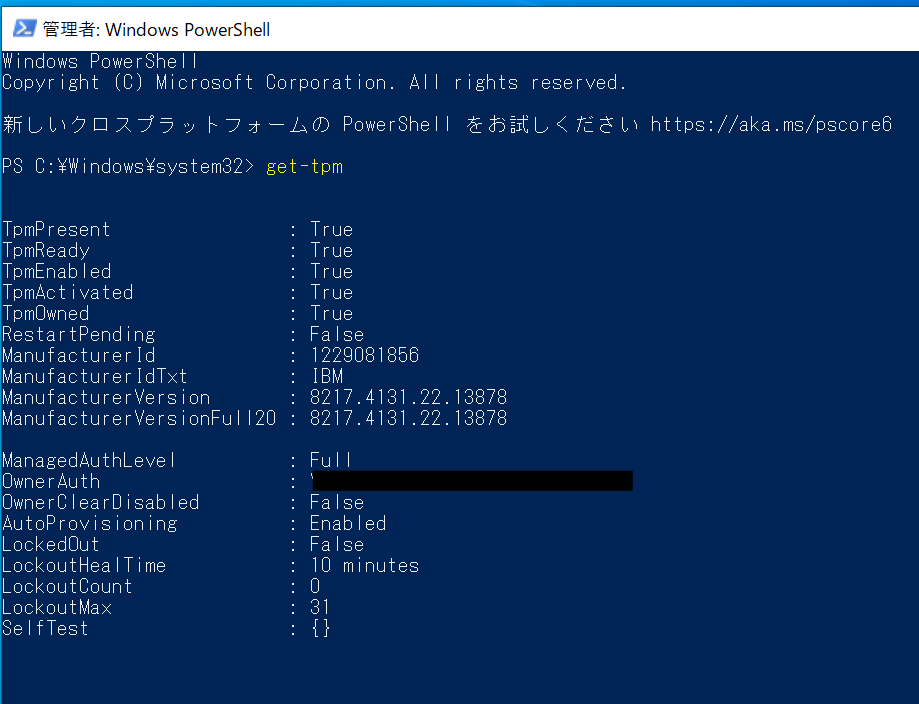
仮想マシンを一旦シャットダウンします。(シャットダウンしないとハードウェア構成の変更が反映されません。)
再び仮想マシンを起動させた後にPowershellで確認すると仮想マシンにTPMデバイスが認識されました。
手順2: 仮想マシンにEFIディスクの追加
設定
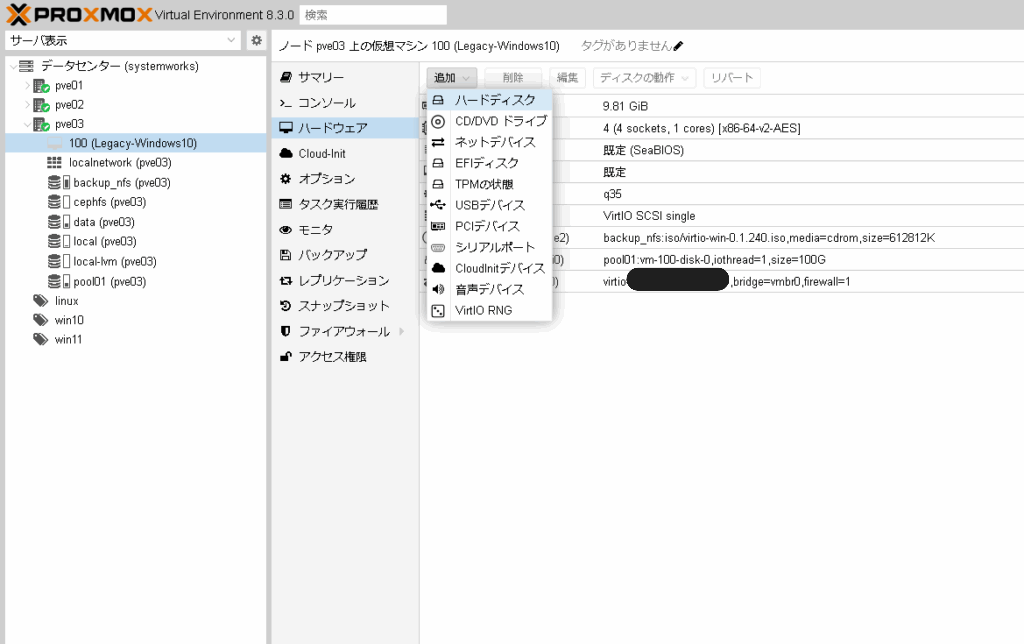
ProxmoxVEのWeb管理画面から対象のVMのハードウェア設定に進み、追加から「EFIディスク」を選択します。
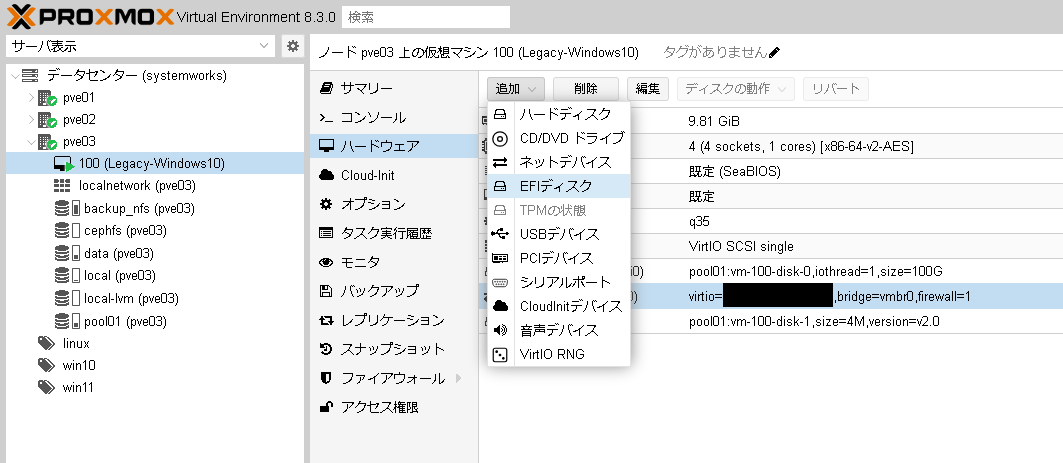
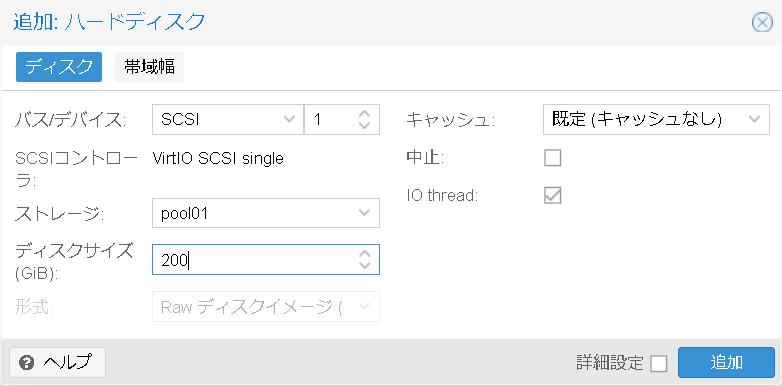
EFIストレージを選択します。EFIストレージは仮想マシンのディスクイメージを配置しているストレージを選択しOKを押します。
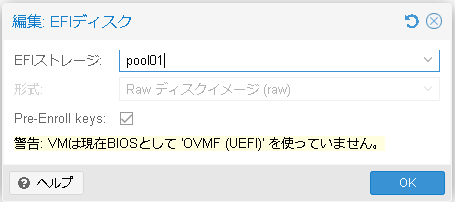
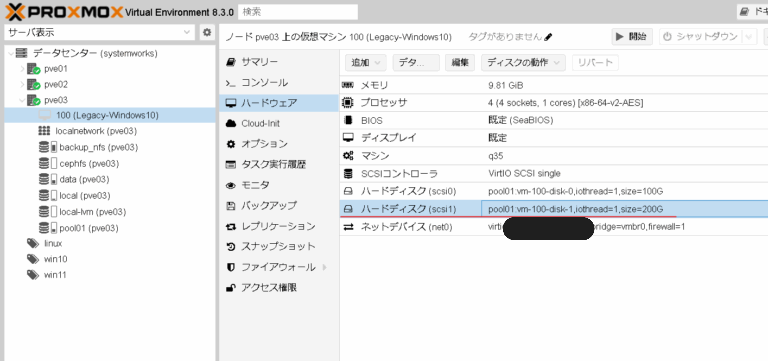
仮想マシンを一旦シャットダウンします。(シャットダウンしないとハードウェア構成の変更が反映されません。)
手順3~4は以上です。次回に続きます。
当社製のハードウェアをご購入の際にWindows10、Windows11を仮想マシンとして動作可能なProxmoxVEのインストールサービスを承っております。
ProxmoxVEではVMwareESXiからもWindows10の移行を簡単に行う事が可能です。
https://blog.systemworks.co.jp/?p=2080
ProxmoxVEのHCIの環境構築サービスも始めました。
是非お気軽にお問い合わせください。
https://www.systemworks.co.jp/hci.php