はじめに
前回の第5回から続き、第6回目は手順6をご紹介します。
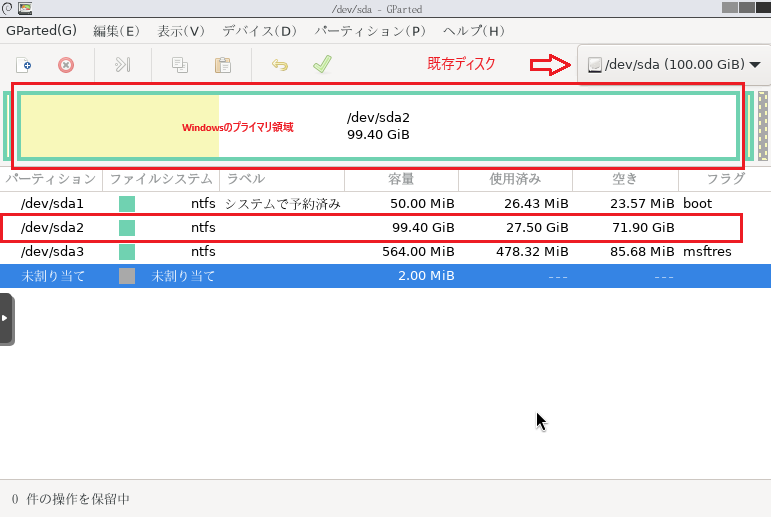
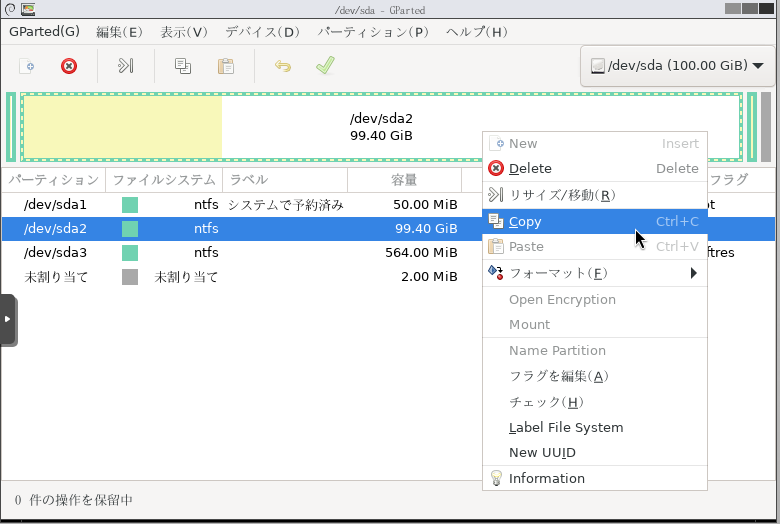
前回は既存ディスクから新規ターゲットディスクにWindowsのプライマリ領域をクローンしました。
今回の手順では新規ターゲットディスクのEFIシステムパーティションにWindowsのブートローダーをインストールしUEFIブートが可能な状態にします。
| 手順1:仮想マシンに Windowsの移行先の新規ターゲットディスク追加、パーティション作成 |
| 手順2: ソースディスク(既存のディスク)のプライマリパーティションのNTFS整合性チェック |
| 手順3: 仮想マシンにTPMデバイスの追加 |
| 手順4: 仮想マシンにEFIディスクの追加 |
| 手順5: gpartedによる既存ディスクのプライマリパーティションをターゲットディスクにクローン |
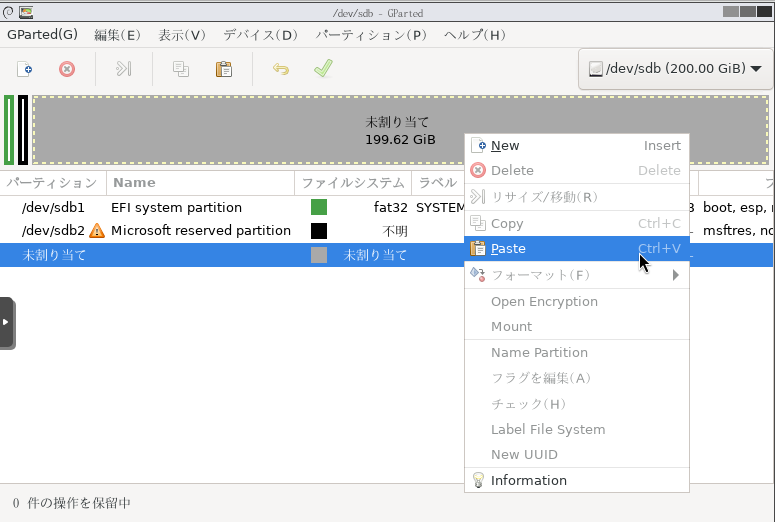
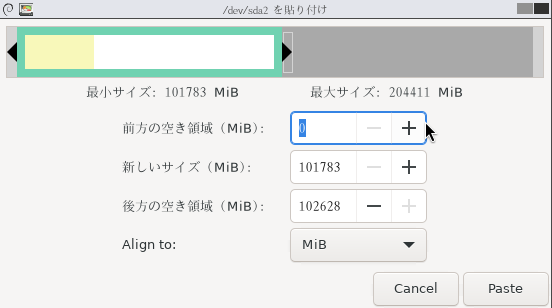
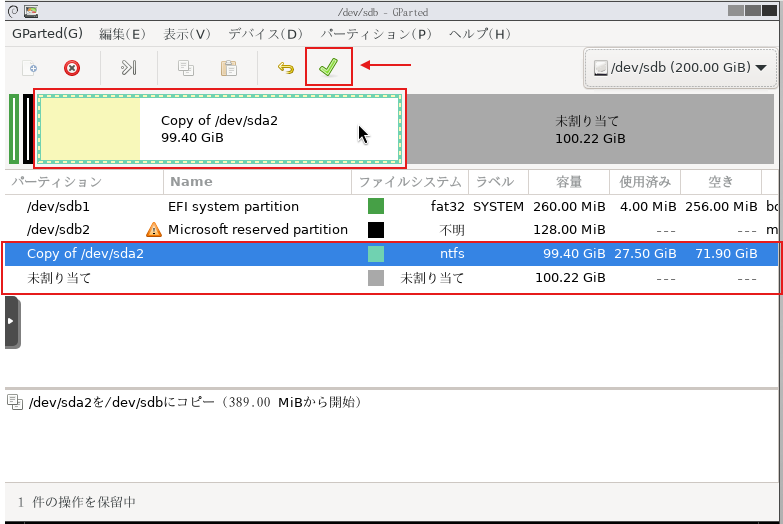
| ★手順6: ターゲットディスクのプライマリパーティションのブート構成をEFIシステムパーティションに作成 |
| 手順7: ターゲットディスクからWindows10をUEFIブートで起動しディスクの管理からプライマリ領域の拡張を実行 |
| 手順8: Windows 11 インストール アシスタントを使用してアップグレード |
手順6: ターゲットディスクのプライマリパーティションのブート構成をEFIシステムパーティションに作成
一旦、元々の既存ディスクからWindowsを起動して、diskpartおよびコマンドプロンプトで新規ターゲットディスクのブートローダーの設定を行います。
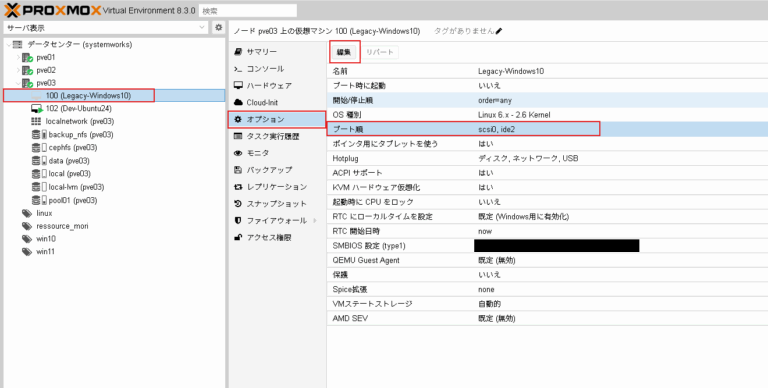
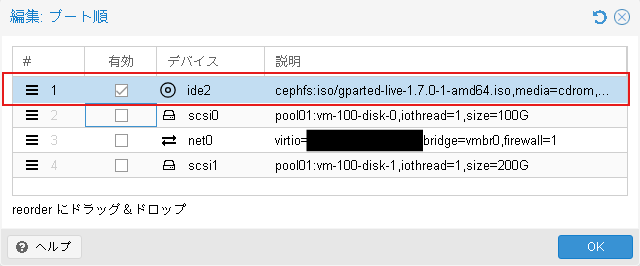
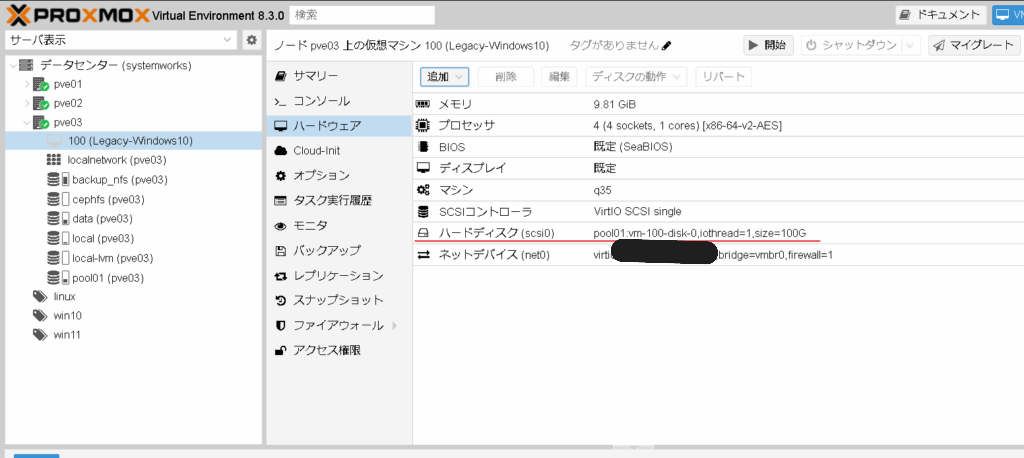
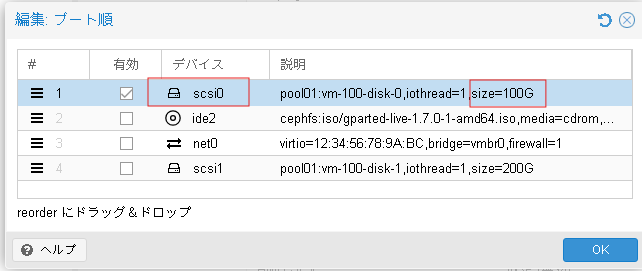
仮想マシンのブート順を編集します。既存ディスクのscsi0 100GBディスクが一番になるように設定します。
仮想マシンを起動します。仮想マシンを起動するとscsi0のWindows10が起動します。
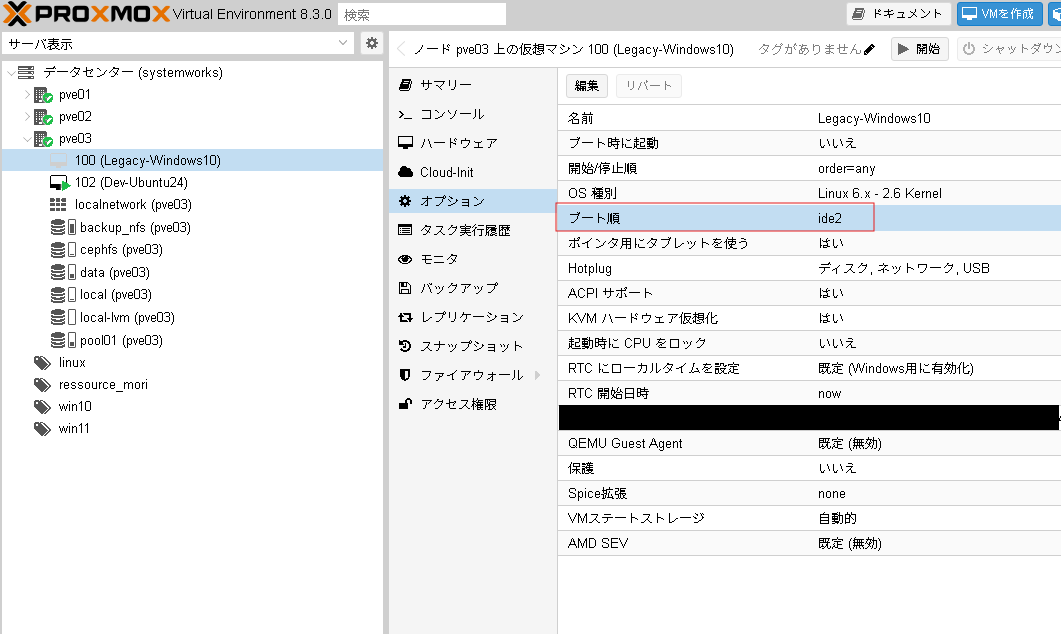
なお、この時点ではもともとの既存ディスクから起動しただけなのでまだlegacy bootでMBRパーティションのWindows10が起動します。
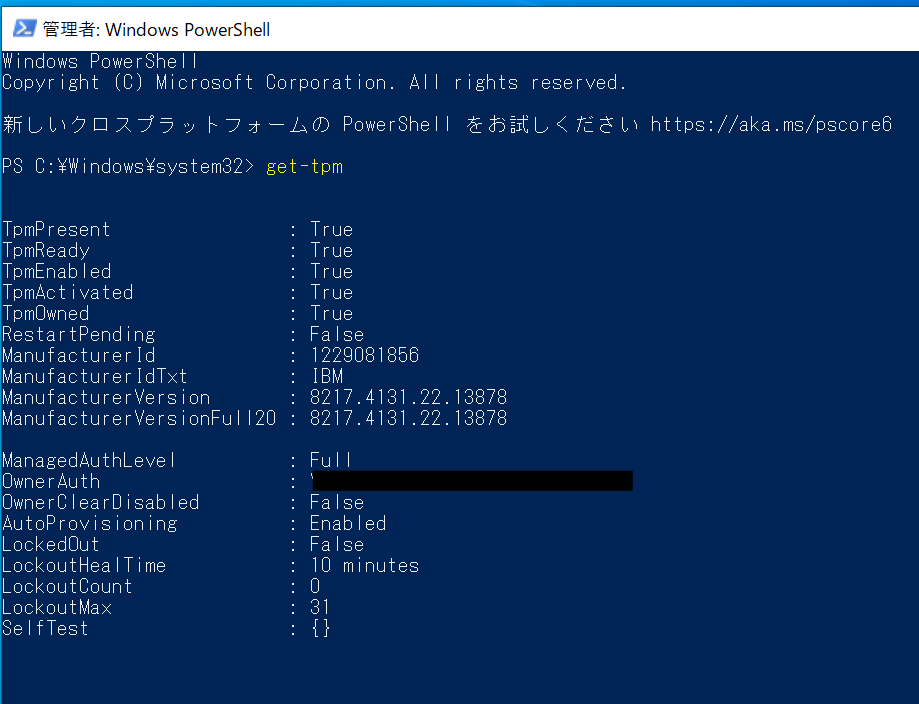
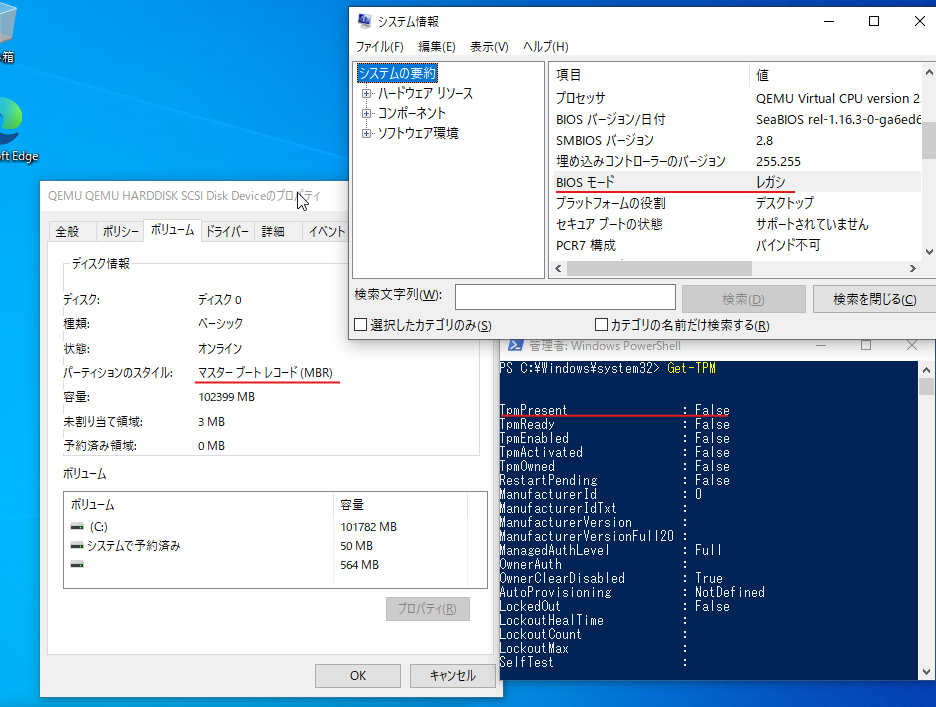
Windows10上のmsinfo32の画面
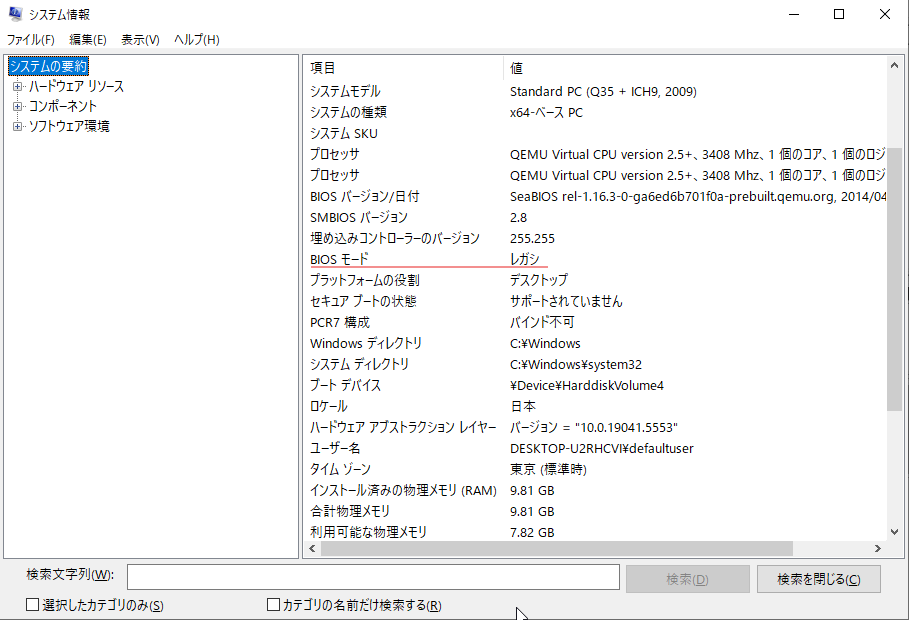
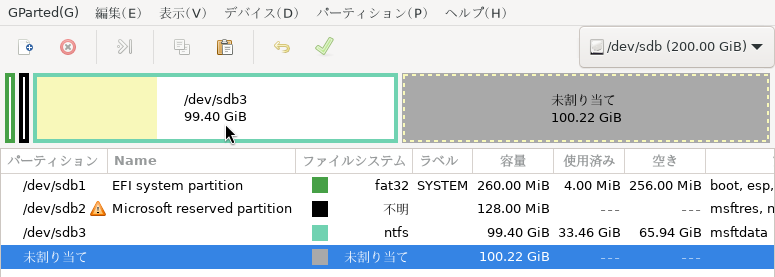
ディスクの管理を確認します。
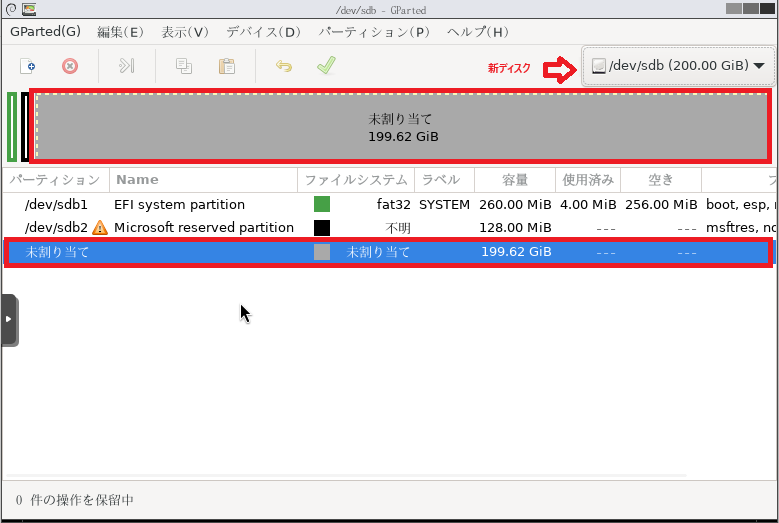
ディスク0が新規ターゲットディスクでその中のDドライブがクローンしたWindowsのプライマリパーティションという形になります。
このDドライブのWindowsプライマリパーティションを起動させるためのブートローダーをディスク0先頭のEFIシステムパーティションにインストール/構成する必要があります。
Windows10上のディスクの管理の画面
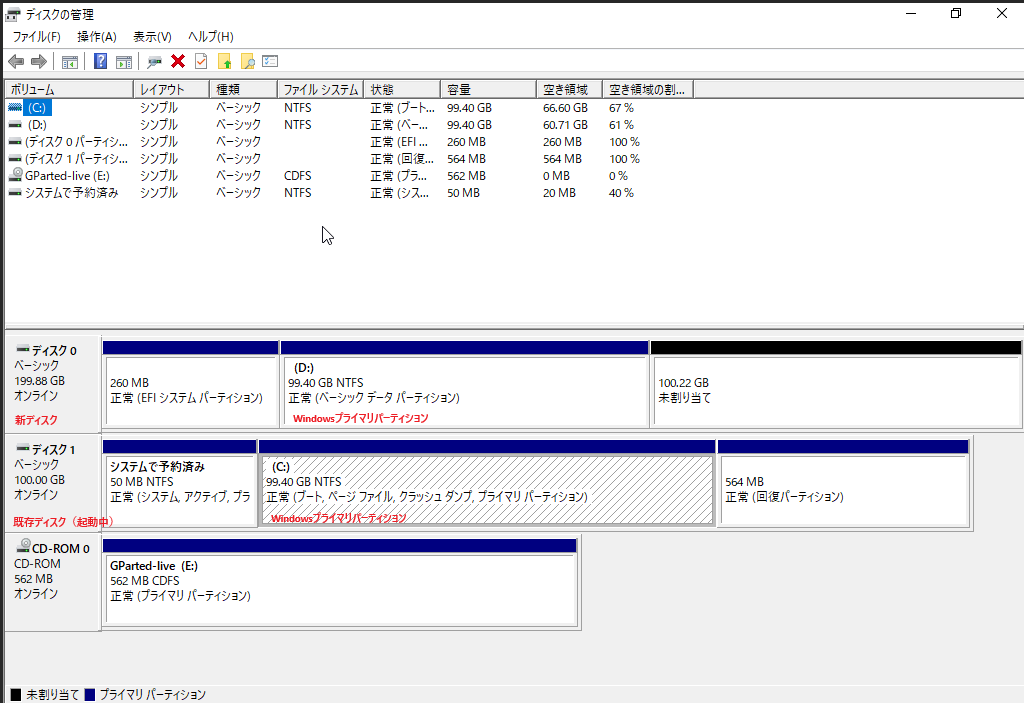
ここからEFIシステムパーティションにブートローダを設定する作業に入ります。
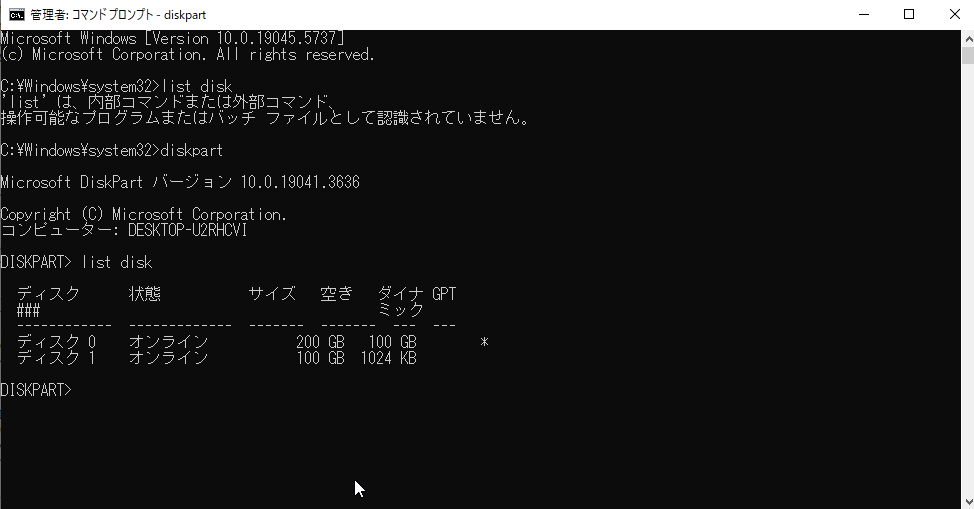
まずはコマンドプロンプトを開きます。
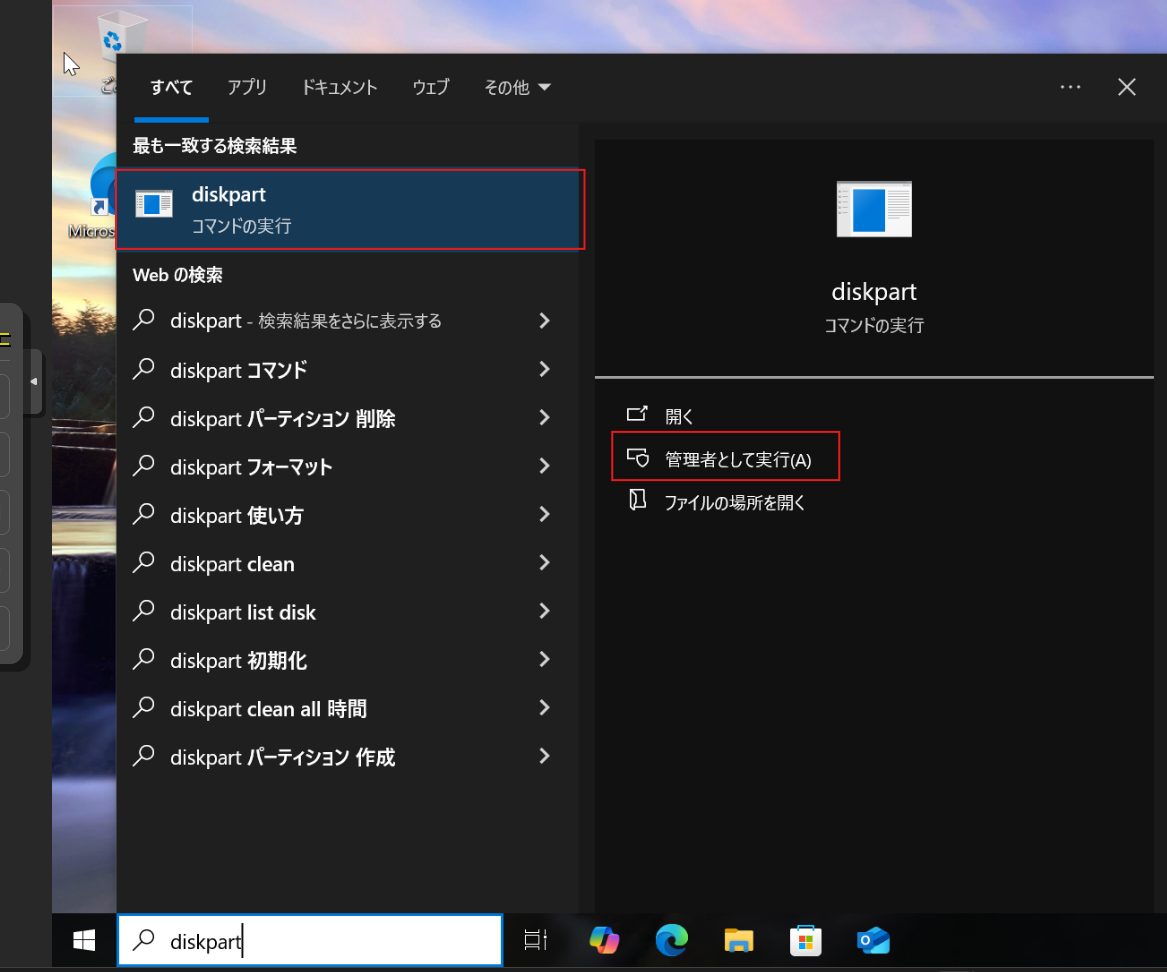
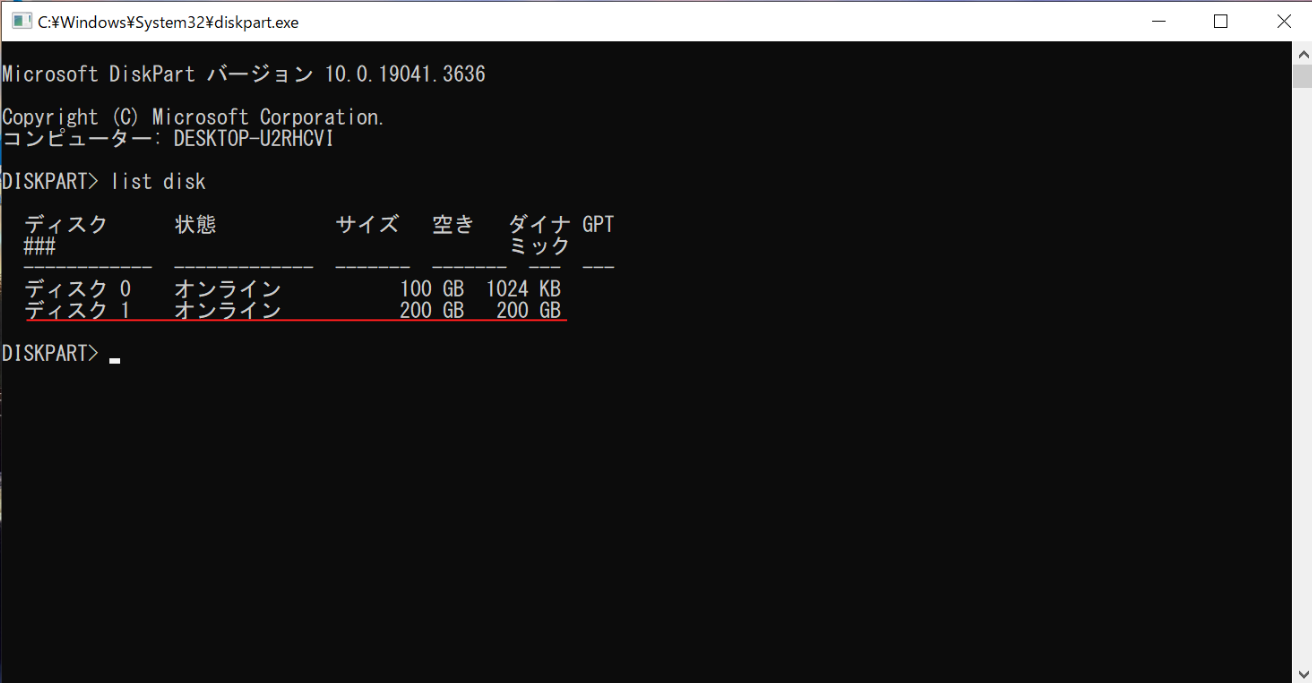
diskpartを実行しlist diskでディスクのインデックスを確認します。
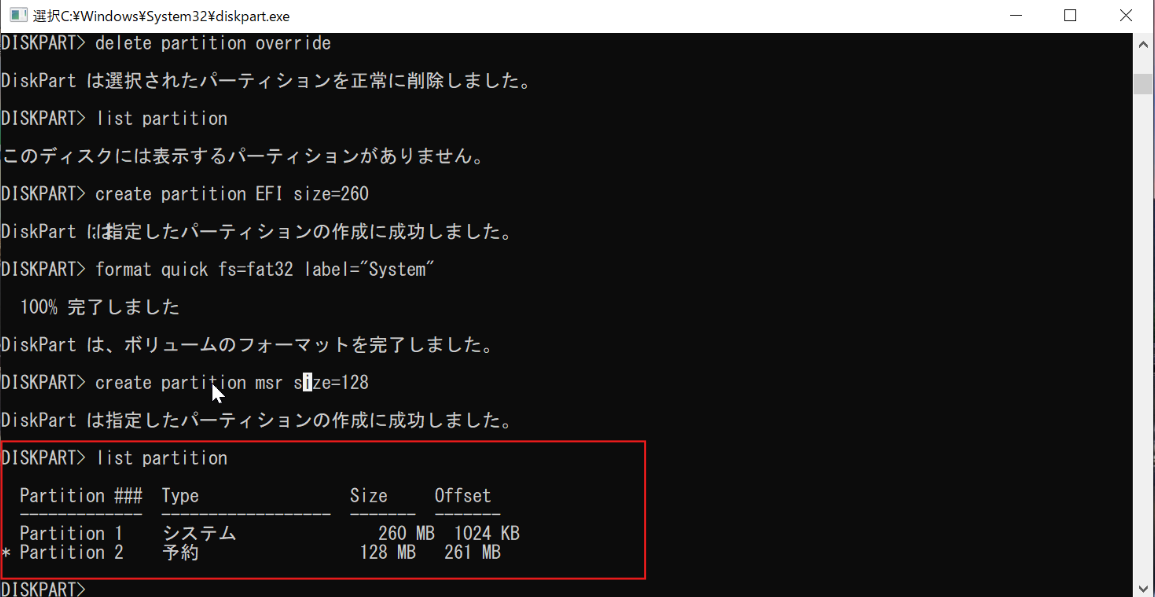
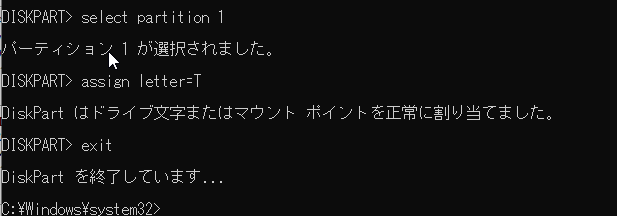
新規ターゲットディスク(ディスク0)を選択してlist partitionでパーティション構成を確認します。
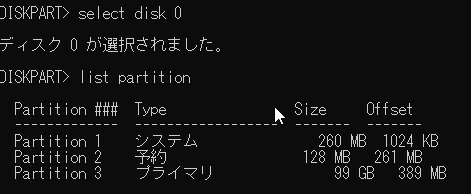
EFIシステムパーティションであるpartition 1を選択してドライブレターTをアサインします。(ドライブレターは重複していなければなんでも良いです。今回は重複しにくくターゲットのTと意味があるようなレターとしました。)
アサインされたらdiskpartを終了します。
引き続きコマンドプロンプトで下記のコマンドを実行します。
bcdboot D:\Windows /s T: /f UEFI
これでディスク0の先頭のEFIシステムパーティションにディスク0のWindows10のプライマリパーティションのブート情報が作成されました。
ここまでくれば後は新規ターゲットディスクのGPTパーティション中のWindows10をSecure boot有効状態でUEFIブートする事が可能です。
次回はついに新規ターゲットディスクからWindowsを起動します。
最後に
当社製のハードウェアをご購入の際にWindows10、Windows11を仮想マシンとして動作可能なProxmoxVEのインストールサービスを承っております。
ProxmoxVEではVMwareESXiからもWindows10の移行を簡単に行う事が可能です。
https://blog.systemworks.co.jp/?p=2080
ProxmoxVEのHCIの環境構築サービスも始めました。
是非お気軽にお問い合わせください。
https://www.systemworks.co.jp/hci.php