ARM64命令セット Armv8 CPUな Ampere Altra Q80-30 搭載サーバ GIGABAYTE E252-P31 をテストしています。
https://www.gigabyte.com/jp/Enterprise/Edge-Server/E252-P31-rev-100
前回の記事
M.2 NVMe SSDも普通に認識します。デバイス /dev/nvme0n1 です。
そこにUbuntu 20.04をインストールしました。特別な設定もなくインストールと起動が確認できました。
また INTEL x550 NIC 普通に認識し動作します。
主なハードウェア組合せ あまり気にしなくてもよさそうです。
次は高負荷なテストもやってみよう。
つづく
iWARP動作検証 つづき②
iWARP (Internet Wide-Area RDMA Protocol) は、TCP/IPネットワーク経由でRDMAを実装するネットワークプロトコルです。
前回の記事
Chelsio NICは、ドライバ ダウンロードしてmake一発で環境構築できるので楽ですが、Intel NICはどうもそう楽ではなさそう。
ドキュメントをなんとなく見たところ、どうやら 3つのソフトウェア構成が必用そうです。
・NICドライバ
・NIC RDMAドライバ
・RDMA Coreライブラリ
簡単に環境構築できることは楽で良いですが、もう少し手間を学んだほうが良いのでしょう。
つづく
ARM動作確認 つづき②
ARM64命令セット Armv8 CPUな Ampere Altra Q80-30 搭載サーバ GIGABAYTE E252-P31 をテストしています。
https://www.gigabyte.com/jp/Enterprise/Edge-Server/E252-P31-rev-100
前回の記事
MegaRAIDコントローラのFW設定がUEFI BIOS上にエントリが追加されるところまでは前回確認できたので、さっそくVD作成しそこにOSをインストールし起動ドライブとして動作させてみたところ、難なく起動できました。特に従来のx86サーバと違いは見当たりません。
では次にOS上からMegaRAIDコントローラをどう管理すべきか?
x86環境では以下が一般的
・MegaRAID Storage Manager(MSM)
・StorCLI
・LSI Storage Authority(LSA)
これらARM環境で動作するか確認が必用です。
つづく
iWARP動作検証 つづき①
iWARP (Internet Wide-Area RDMA Protocol) は、TCP/IPネットワーク経由でRDMAを実装するネットワークプロトコルです。
前回の記事
iWARP対応しているNICはどこのメーカーか?
ザックリ調べてみたところ以下
Intel
Chelsio
Marvell
それ以外もあるかもしれない。
ChelsioはiWARPに関して様々なドキュメントやホワイトペーバーが用意されており安心感があります。実際に以下OSをインストールしてみましたが、特に悩まず動作環境を構築できました。
CentOS 7
Rocky Linux 8
Rocky Linux 9
Ubuntu Desktop 20.04
Ubuntu Server 20.04
Chelsioドライバは以下よりダウンロードできます。
https://service.chelsio.com/
2023年5月30日時点での最新Linuxドライバ バージョンは v3.18.0.0 です。
ドライバ ダウンロードし解凍したディレクトリで
$ make list_kernels
実行するとサポートカーネルバージョンのリストが見れます。
(以下 Ubuntu Server 20.04 に関係しそうな部分のみ抜粋)
$ make list_kernels
5.4.0-26-generic
5.4.0-54-generic
5.4.0-65-generic
5.4.0-81-generic
5.4
例えば Ubuntu Server 20.04 の現時点での最新カーネルバージョンは
5.4.0-149-generic
です。
最後の 5.4 の範囲でサポートされているようです。
つづく
ARM動作確認 つづき①
ARM64命令セット Armv8 CPUな Ampere Altra Q80-30 搭載サーバ GIGABAYTE E252-P31 をテストしています。
https://www.gigabyte.com/jp/Enterprise/Edge-Server/E252-P31-rev-100
前回の記事
UEFI BIOSにx86エミュレーションの設定があります。
有効範囲がOption ROMとEFIシェルまでのようです。
これ使えばMegaRAIDコントローラのFW設定がUEFI BIOS上にエントリが追加される??
やってみました。
結果は期待通りの動きになりました。
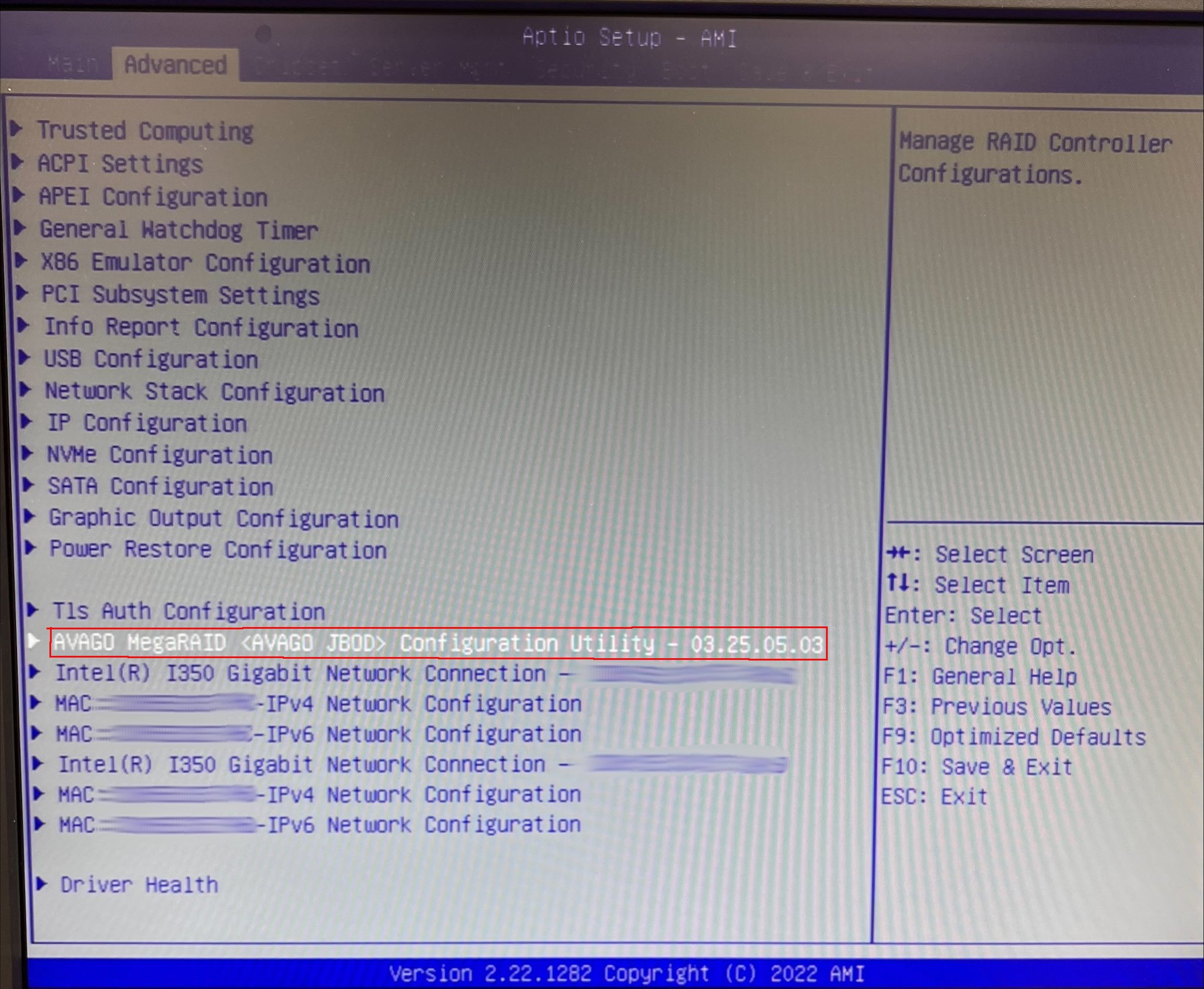
次はOS上の認識や動作を見てみます。
つづく