はじめに
本番環境のProxmoxVEのHCIクラスタの運用において、一般的にはHCIクラスタノードマシンと別途に専用のバックアップサーバーマシンを用意します。専用のバックアップサーバーを用意するのは可用性や冗長性や機密性といったセキュリティの観点からも非常に重要です。
HCIクラスタノード群とバックアップサーバーマシンを同時に用意できれば理想なのですが、しかしながら様々な事情でHCIクラスタの後にバックアップサーバー用意される場面も考えられます。
手元にProxmoxVE HCIクラスタは有るけども、バックアップ用の物理マシンが用意できてない・・・、でもバックアップサーバーを用意してクラスタのバックアップ検証は実施したい・・・!という時に、もしかしたら役に立つ、ProxmoxVEのHCIクラスタ全体の仮想マシンのバックアップを物理ディスク1台で試みるアイディアをご紹介します。
この方法は本番運用には向きませんが、検証段階では様々な条件が試せますので場面に合わせてご活用いただければ幸いです。
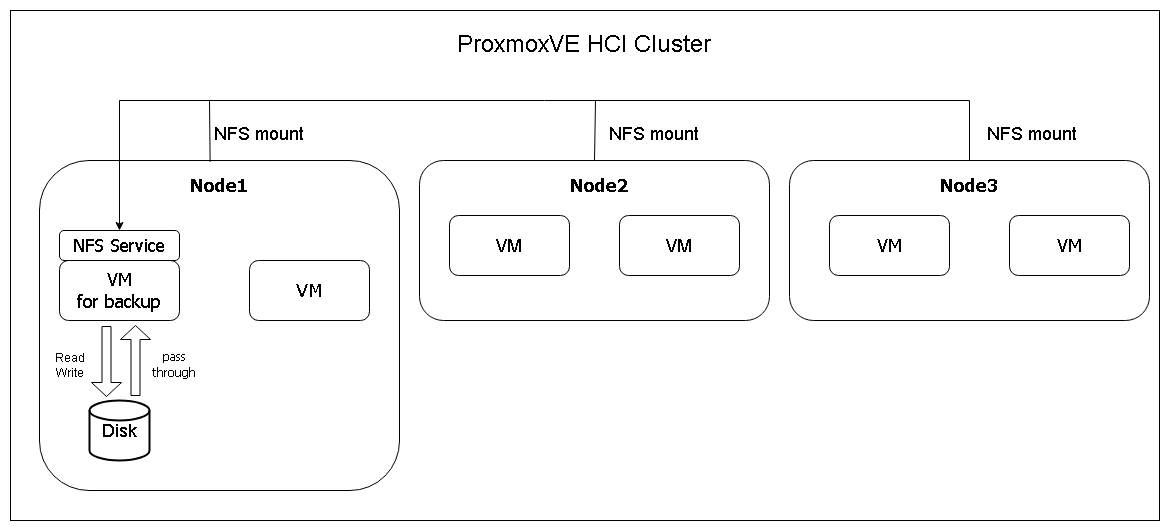
先にこの方法の概要だけ説明すると、
- ProxmoxVE HCIクラスタ上のバックアップ用仮想マシンに物理ディスクをパススルーし、
- マウントしたパススルー物理ディスクを仮想マシンOS機能でNFSエクスポートして、
- ProxmoxVE HCIクラスタ全ノードからNFS越しに仮想マシンを通じて物理ディスクにバックアップを行う
という方法です。
方法
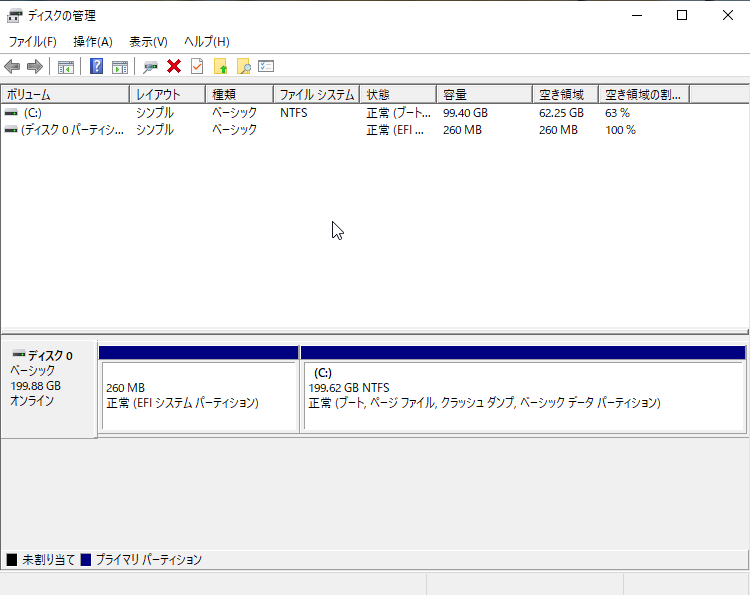
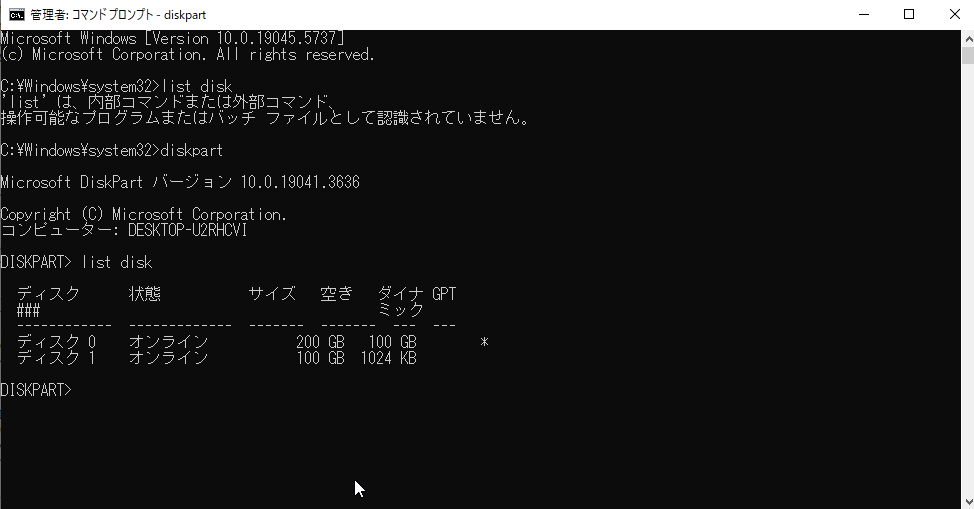
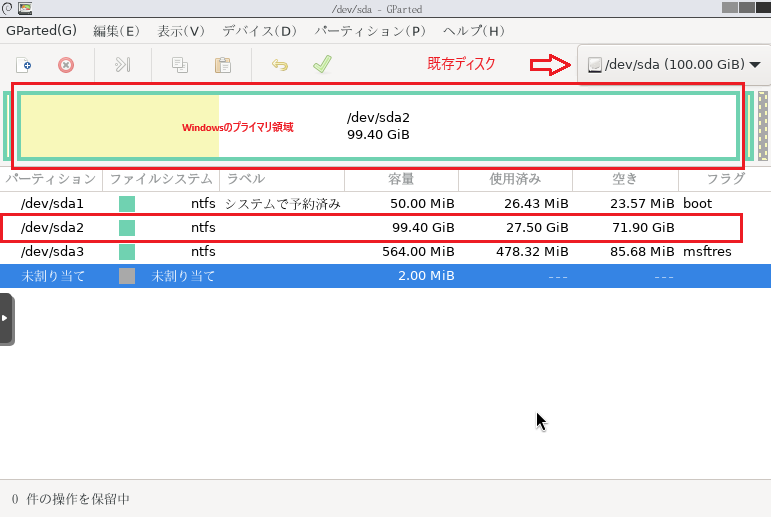
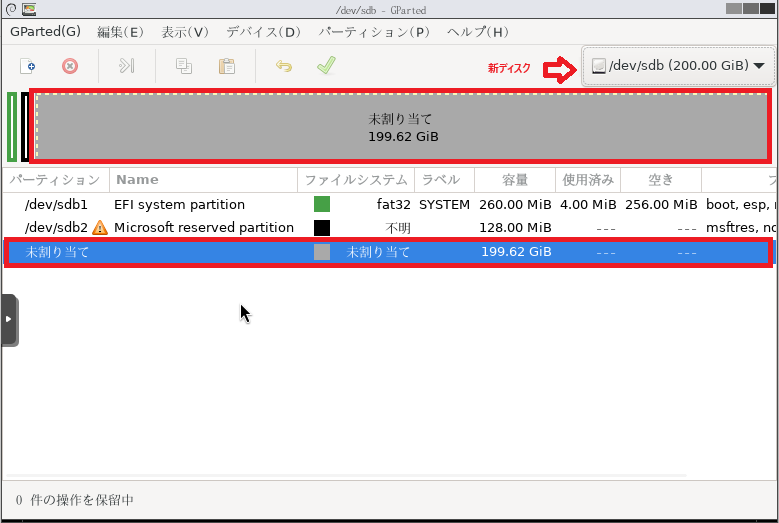
1. 物理ディスク1台をHCIクラスタノードの1台に搭載
バックアップ用の仮想マシン分の空リソースがあるノードに物理ディスクを搭載します。
※ホットプラグ可能なスロットを備えたケースでProxmoxVEクラスタが運用されているとスムーズにディスクの追加やメンテナンスができるのでとても便利です。
※当社では拡張性やメンテナンス性も含めてHCIに適したハードウェア選定のご相談・ご提案を承っています。是非お問い合わせください。
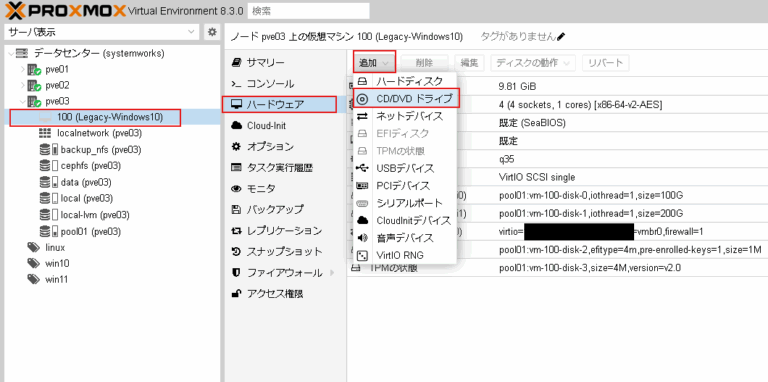
2. 仮想マシンを作成
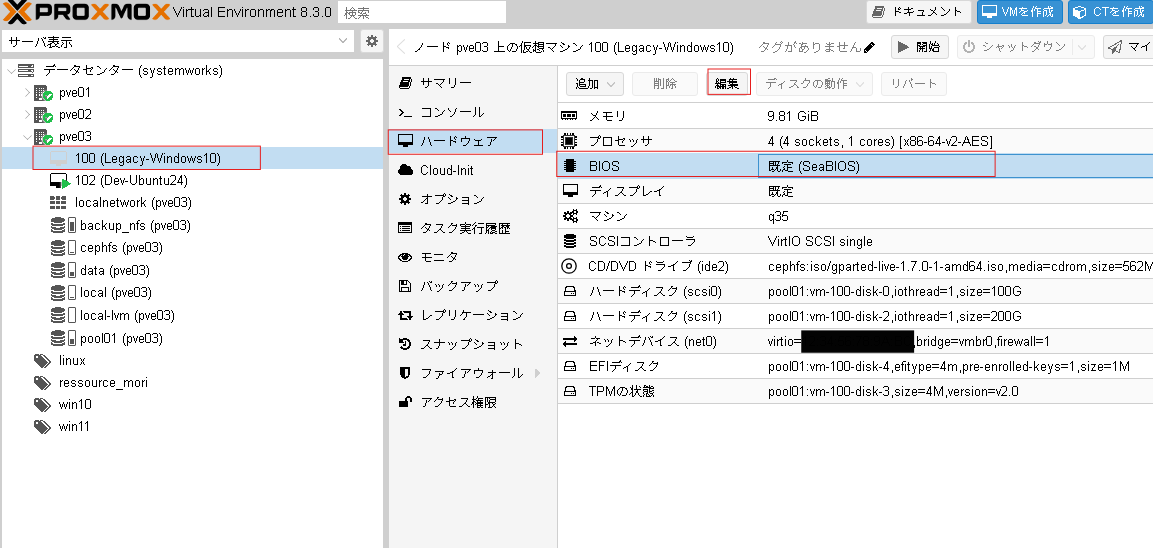
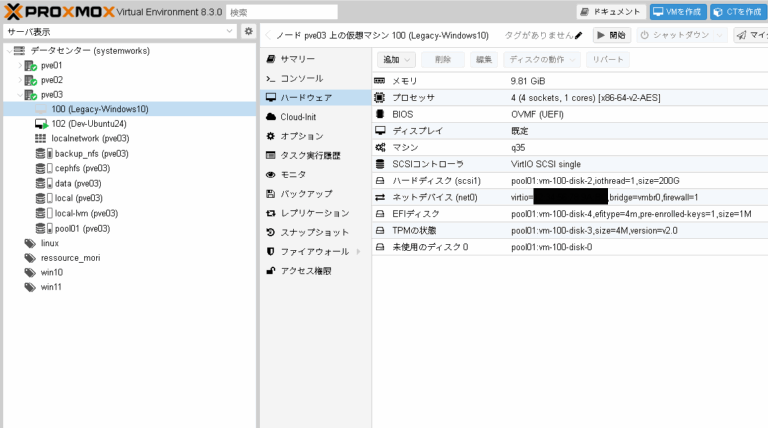
HDDを搭載したノード中に、下記の条件を満たした仮想マシンを作成します。
- 仮想マシンのOSはUbuntuなどの一般的なLinuxもしくはPBS(Proxmox Backup Server)を選択します。
※今回はUbuntuで検証しました。
※過去にPBSでの検証も行いましたがバックアップ可能でした。 - 仮想マシンのOS用の仮想ディスク領域を用意する。
- 仮想マシンのネットワークはすべてのHCIクラスタノードからアクセスできるように設計します。(ネットワークセグメントやファイアーウォールなどは環境に合わせて適切なセキュリティ対策を行ってください。)
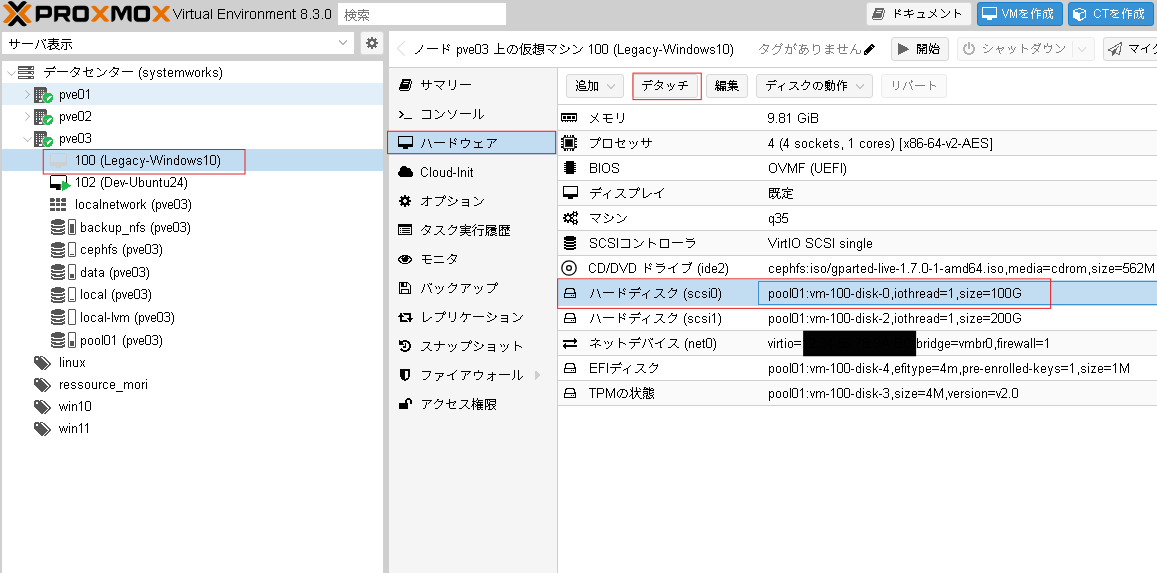
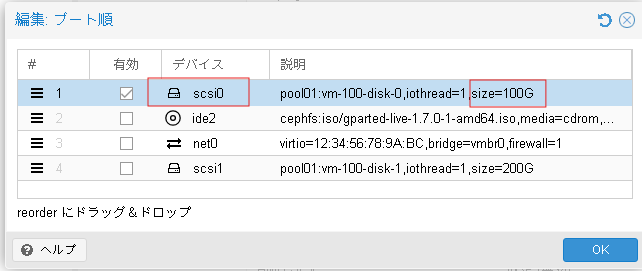
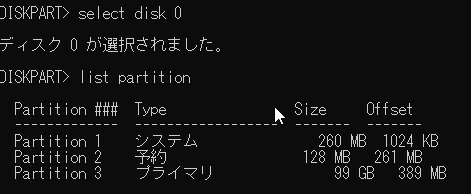
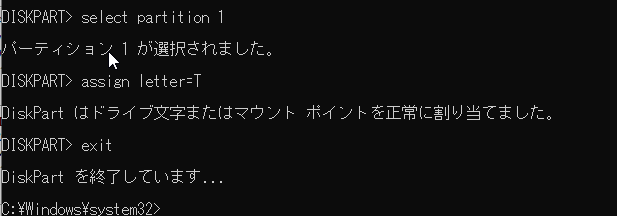
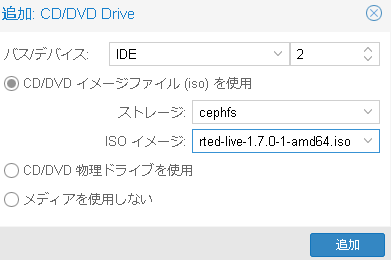
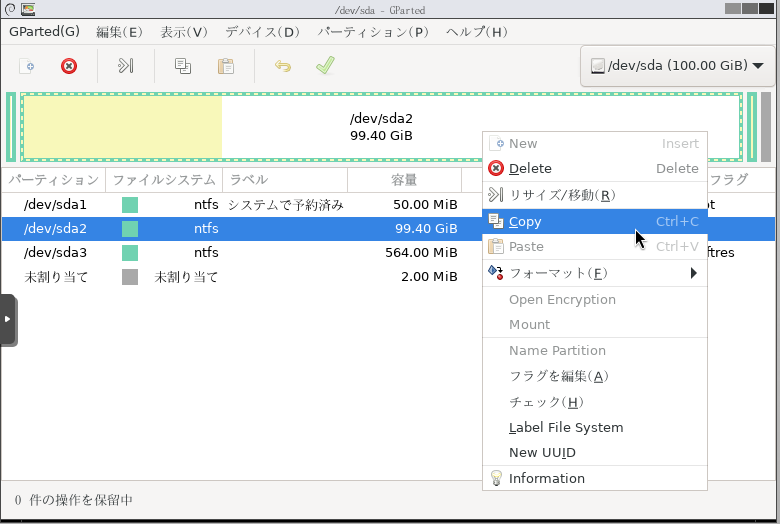
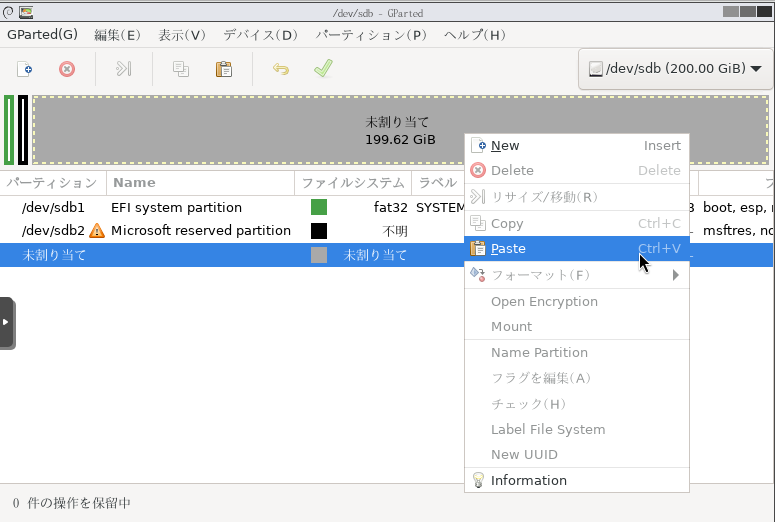
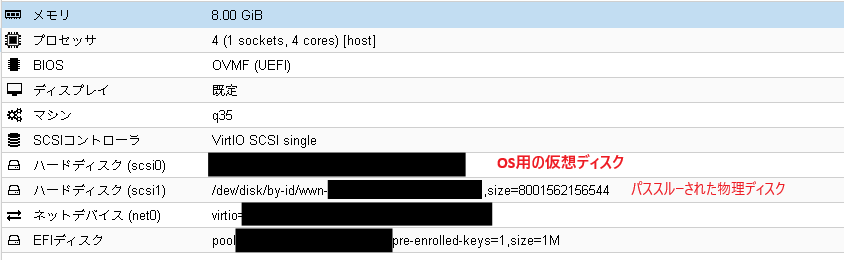
- 仮想マシンに搭載した物理ディスクをパススルーします。
仮想マシンにディスクをパススルーする方法は下記のページに詳細が記載されています。
https://pve.proxmox.com/wiki/Passthrough_Physical_Disk_to_Virtual_Machine_(VM)
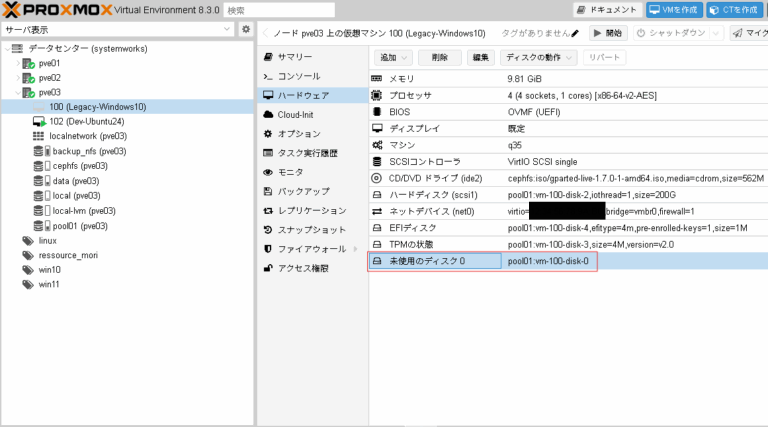
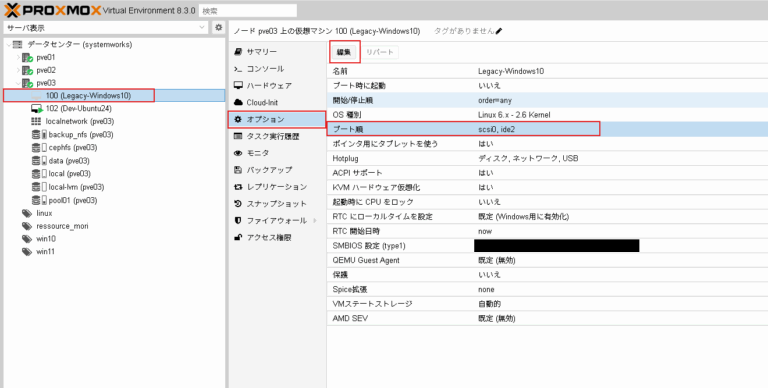
当社での検証時には下記のような仮想マシンのハードウェア構成になりました。
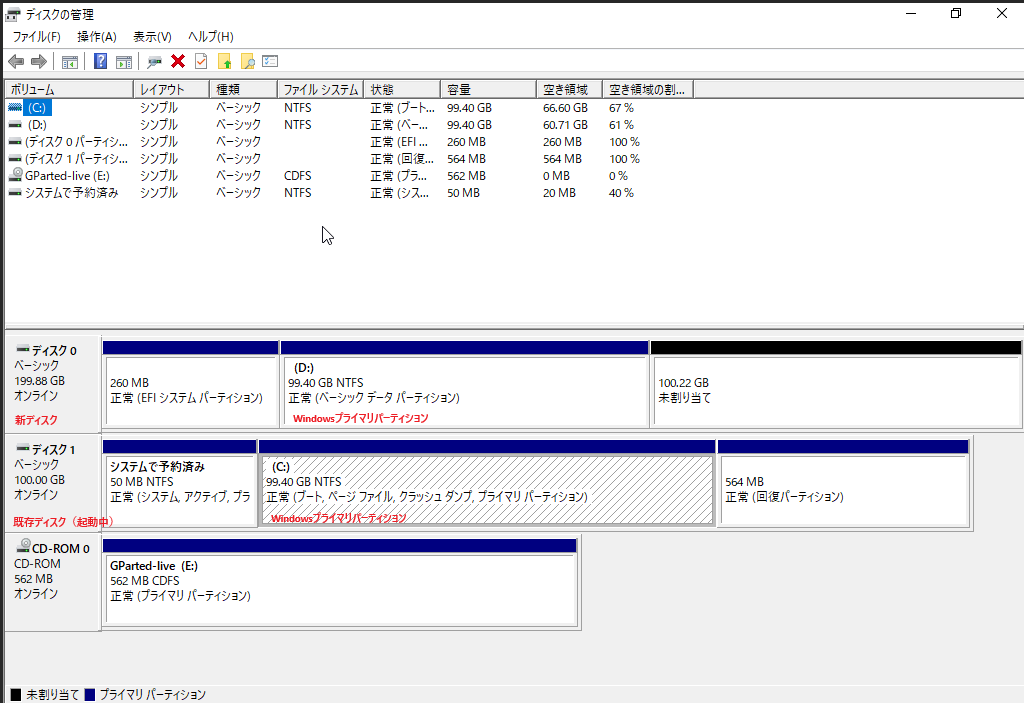
3. 仮想マシンのOSにパススルーしたディスクをマウントし、NFSエクスポートする。
今回の検証ではNFSを使用します。
なお、実際にお試しの場合はProxmoxVEに適合する形式でのエクスポートであればどの形式でも構いません。ProxmoxVEがサポートしているストレージ形式は多岐にわたります。
今回のディスクのマウント方法やNFSエクスポートの方法は一般的なLinuxの方法で問題ありません。
参考
https://documentation.ubuntu.com/server/how-to/networking/install-nfs
仮想マシンのIPアドレスとエクスポートするディレクトリの情報はこの後使用するのでメモしておいてください。
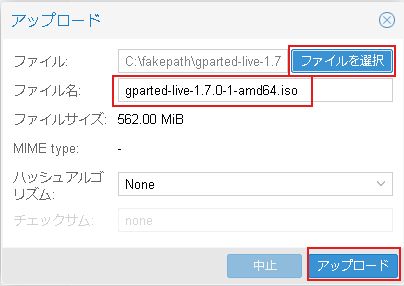
4. ProxmoxVEのweb画面からNFSストレージを登録する
ProxmoxVEのWEB管理画面からデータセンター→ストレージ→追加→NFSと進みます。
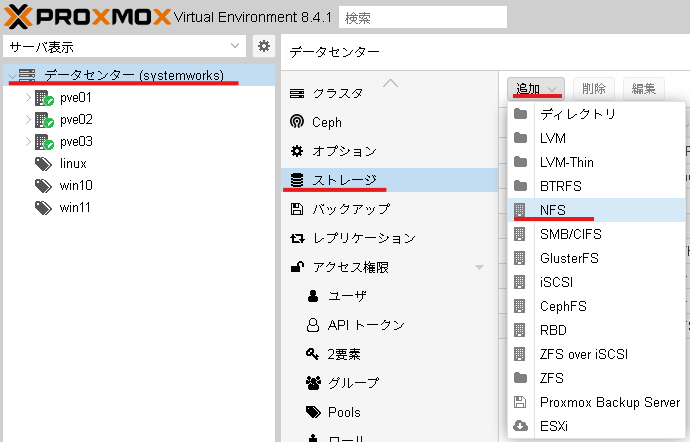
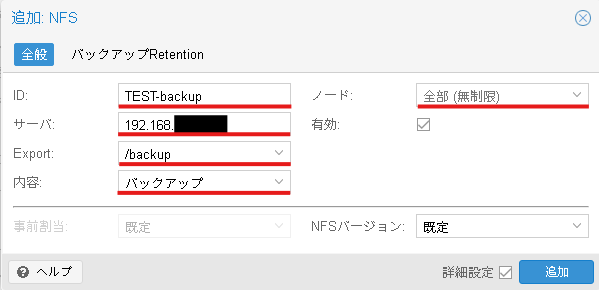
追加:NFSというウインドウが表示されたら下記の様に入力します。
ID: わかりやすいストレージの名前
サーバー: バックアップ用仮想マシンのIPアドレス
Export: バックアップ用仮想マシンでNFSエクスポートしてるディレクトリ
内容:バックアップ
ノード:全部(無制限)
最後に追加ボタンを押します。
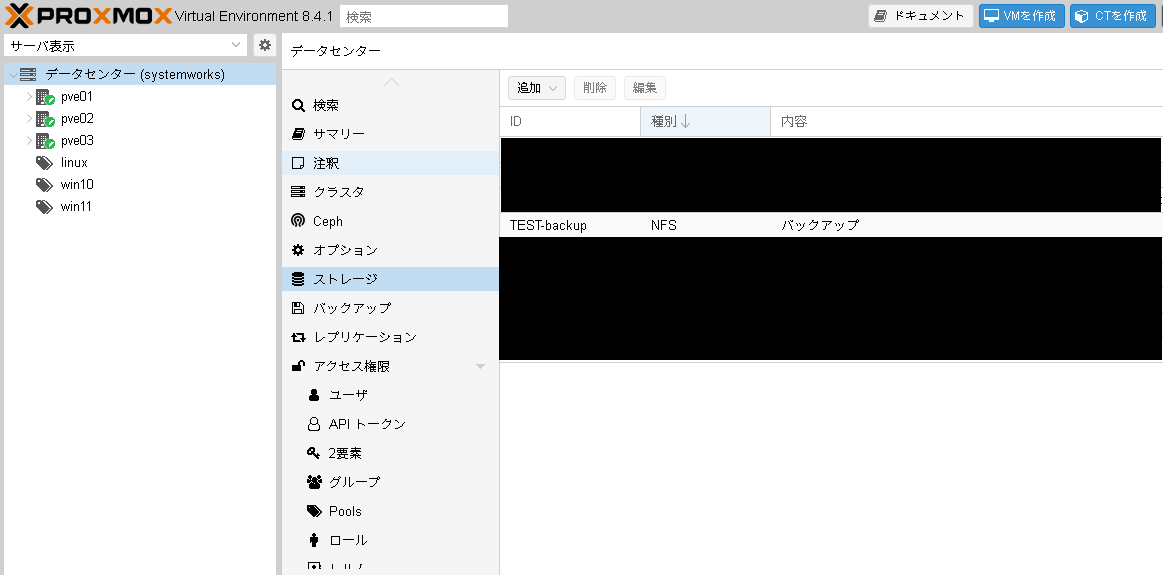
IDに入力した名称でストレージが登録されます。
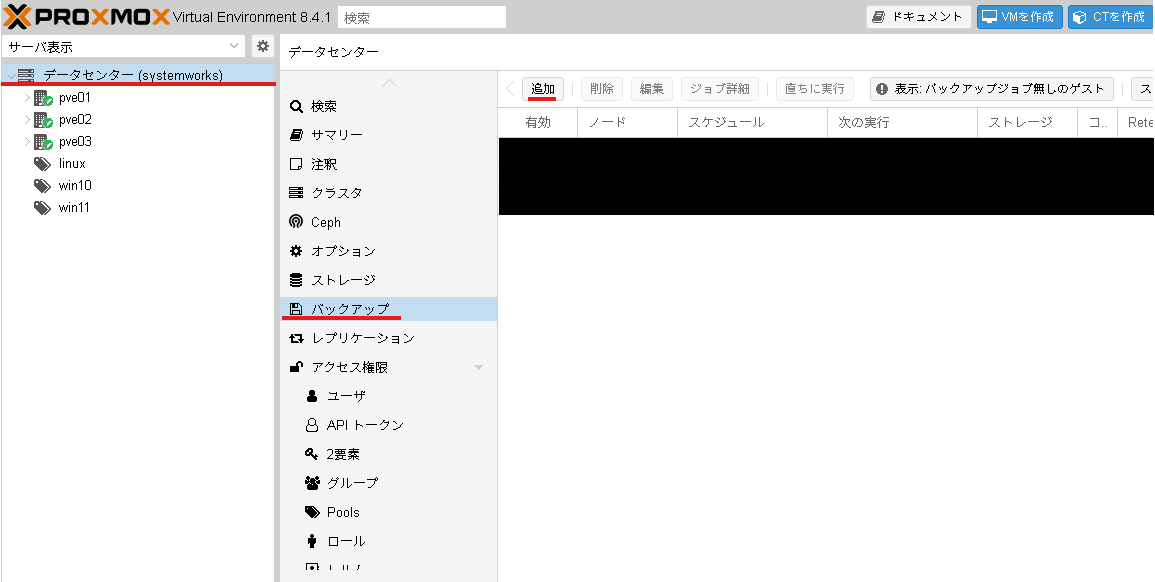
5. バックアップを取る
バックアップスケジュールを設定します。
データセンター→バックアップ→追加を選択します。
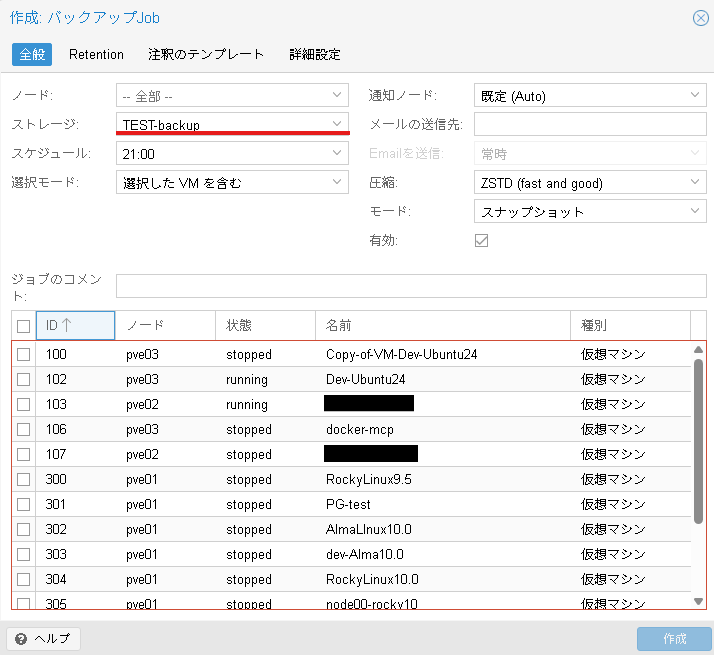
作成: バックアップJobのウインドウが表示されます。
この画面にてすべてのノード上の仮想マシンがバックアップ対象として選択できることが確認できます。
この後、バックアップ設定を適切に設定したところ、スケジュール通りにバックアップが取れました。
手順としては以上です。
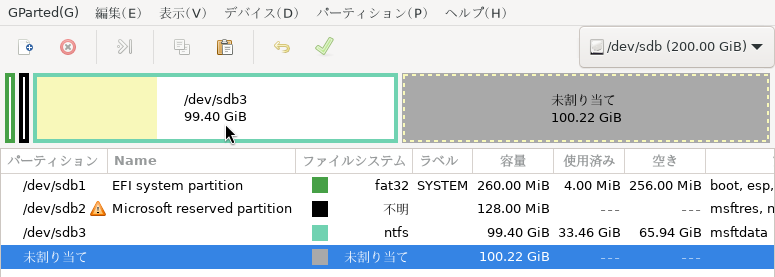
物理ディスク1台あればすべてのノード上の仮想マシンをバックアップ対象にできることが確認できました。
この方法は物理ディスクをパススルーしているため物理ディスクは物理ホストおよび仮想マシンに紐づいています。そのためバックアップ用の仮想マシンはライブマイグレーションには対応しておらず、可用性が通常のHCI上の仮想マシンに比べて劣りますが、OSの選定やスペックなど自由度が高いバックアップ検証ができます。
注意
この方法には重要な注意点があります。
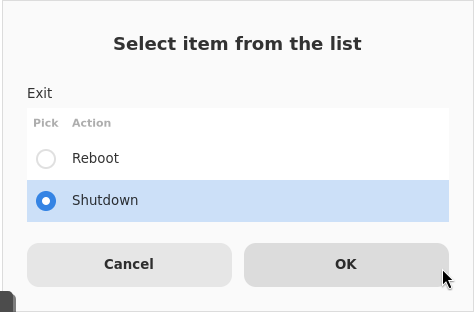
バックアップ用の仮想マシンに自身のバックアップをしない様ご注意ください。
当社での検証中にすべての仮想マシンを対象にバックアップを行う設定をスケジュールしたところ、バックアップ用の仮想マシン自身をバックアップ対象とするバックアップが実行されてしまいました。結果としてバックアップ用の仮想マシンがハングしてしまいました。
バックアップ用の仮想マシンを除いた、全仮想マシンをバックアップしたい場合は下記の画面の様に選択モードを「選択したVMを除外」と設定した上で、バックアップ用仮想マシンにチェックを入れてスケジュールを設定するとバックアップ用の仮想マシンを除いた全仮想マシンのバックアップが設定できます。
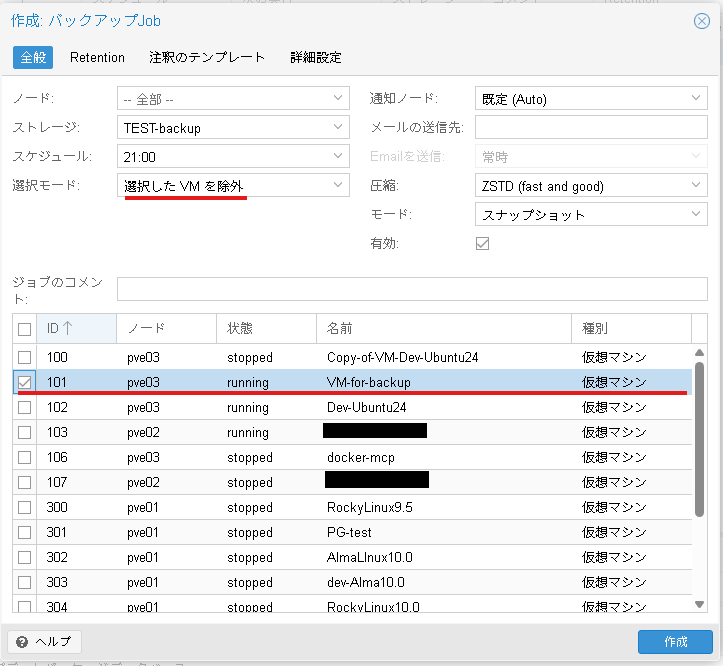
上記のような対策を取ったうえでぜひ色々なバックアップ検証をお試しください。
最後に
当社ではハードウェアをご購入の際にProxmoxVEのインストールサービスを承っております。
ProxmoxVEのバックアップ用のハードウェアのご相談も受け付けております。
ProxmoxVEのHCIの環境構築サービスも始めました。
是非お気軽にお問い合わせください。
https://www.systemworks.co.jp/hci.php